







Chinese Journal of Information Fusion
ISSN: 2998-3371 (Online) | ISSN: 2998-3363 (Print)
Email: [email protected]

Personality testing is a common task in psychology. The traditional method of testing a subject's personality is an artificially designed questionnaire, which is relatively reliable but not particularly efficient. To this end, researchers have proposed several different automated methods of testing personalities. Of these, analyzing user-generated content is one of the most important [1, 2]. Fortunately, social media provides vast quantities of user-generated content to test and, here, text, as the most abundant type of content, has proven to contain rich information that substantially reflects the author's individuality [3, 4]. It is this information that helps us to understand human cognitive and behavioral patterns. As such, personality detection has numerous promising applications in fields such as marketing and social network analysis. Figure 1 provides an outline of how personality detection works in social media texts.
Researchers have long been attempting to identify an individual's personality traits from their writings. Typically, they study the styles that surround people use words, with most articles reporting high within-person stability of language use, which has been linked to personality, psychological interventions, and other phenomena [5, 6, 7, 4]. Moreover, this stability tends to persist no matter how the text is written: as a stream-of-consciousness, as an essay, or in self-narrative format [8, 9, 10].
That said, most of the above studies were conducted in a laboratory setting, where the subjects not only produced writing samples in the lab, but limitations were also placed on the topics to write about and the size of the sample. To address this issue, researchers have turned to more naturalistic writing texts, such as blogs on websites or posts on social media platforms [11, 12, 13, 14]. Here, researchers have found inherent consistency in the personalities implied between the social media texts and normal, freely-written samples. For example, Gill et al. [39] conclude that bloggers tend to adapt to the possibilities of the medium rather than trying to present themselves differently.
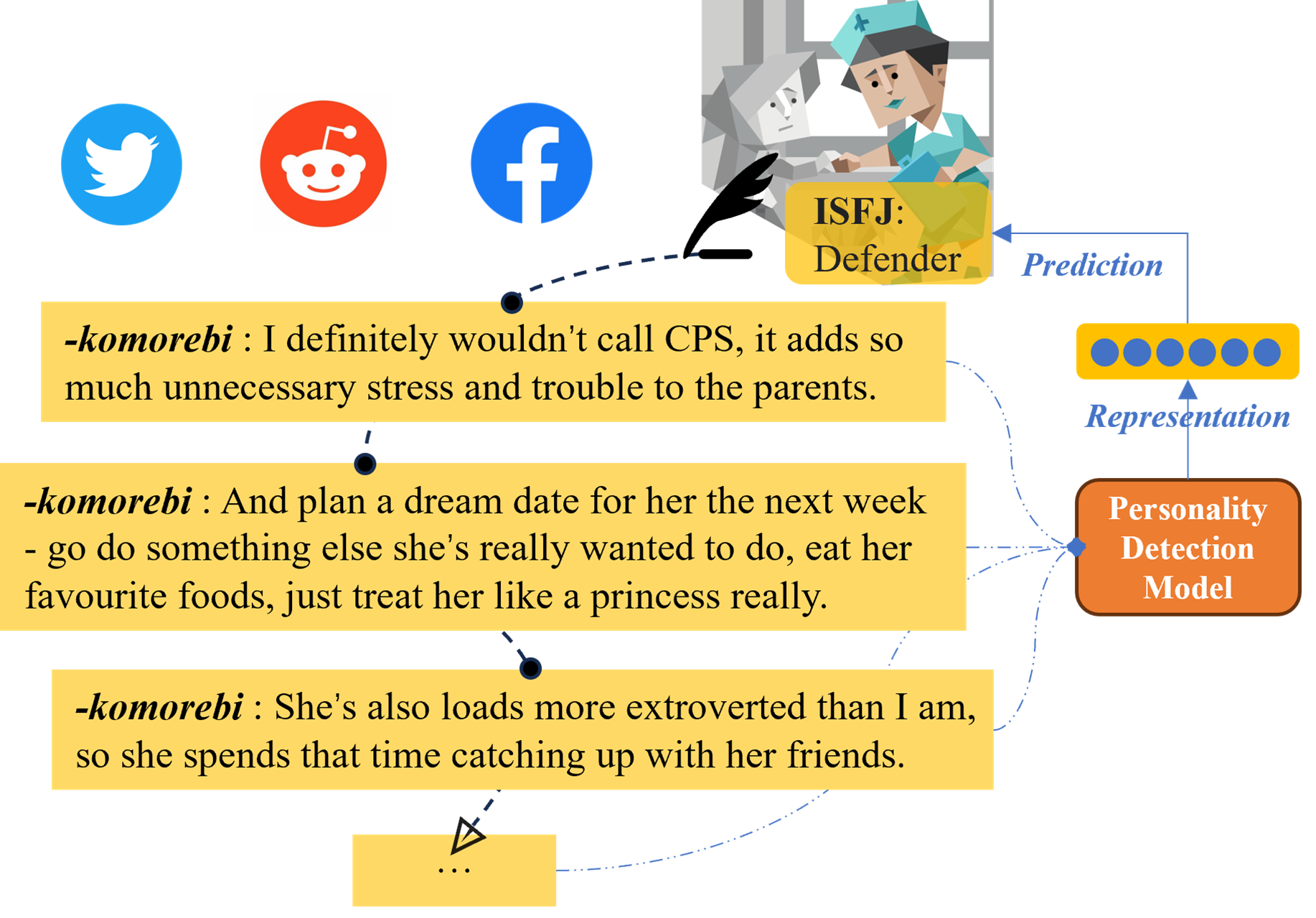
Researchers have also found that linguistic expressions have a significant non-linear correlation to personality traits [1, 6, 7, 8, 9]. In fact, several of the initial advances made in personality detection with texts have been closely related to some of the research findings from psycholinguistics. For example, people who score high on extraversion generally use more social words, show more positive emotions, and tend to write more words but fewer large words [6, 15]. Linguistic Inquiry and Word Count (LIWC) [16] has been one of the most widely used tools for analyzing word use. Emotional dictionaries are also frequently mentioned [17, 18], as emotional experience has proven to be a key factor in personality analysis [19]. Further, many researchers are relying on statistical strategies to build a combined feature set, i.e., a set of word expressions, to feed into traditional machine learning models. The idea is to extract a linguistic feature pattern that can be used to predict personality traits [13, 14, 20] for a better result. These statistical features, such as LIWC, are frequently called (traditional) psycholinguistic features or psycholinguistic clues.
Additionally, numerous researchers have been working on feature engineering as a way of extracting personality-related signals from raw text [18, 21, 22]. For instance, Celli et al. [23] summarized two approaches to personality recognition: bottom-up and top-down. The bottom-up approach seeks cues from the data, like using n-gram features for text classification [24, 11]. Conversely, the top-down approaches use external resources, such as LIWC, to test correlations between word use and personality traits [3]. Further, with the rise of Transformers [25], researchers have turned to Transformer-based pre-trained language models (PLMs) to extract deep semantic features, also sometimes called PLM features. Such approaches have demonstrated encouraging progress [22, 26], generally relegating psycholinguistic features to second place.
One of the most recent advancements in personality prediction has been to measure personality types from social media posts [26, 27]. Given the abundance of diverse text on social media, this has proven to be an easy-access approach that also saves time – especially compared to questionnaire-based approaches [28, 29]. Take blog posts as an example. These are typically short, topic-agnostic documents written in the author's natural style whose content may or may not contain personality clues [30]. To explore these posts for personality detection, one stream of research sees this content converted into graph networks. In turn, these networks reveal the inherent patterns in the structure of the posts [31, 32, 33, 30].
In terms of prediction models, researchers have tried to integrate PLM features and psycholinguistic features using graph representations of the posts [32, 33]. Usually, the psycholinguistic features are used to construct the connection between posts, while the PLM features are used for the representations of each post.
Counter to this graph network-based approach, we propose an attention-based network called IAN. IAN weights the posts according to the psycholinguistic features and produces representations of the posts according to the PLM features, which are then subject to deep classification. Similar to the approaches based on graph networks, IAN uses the psycholinguistic features to mine correlations between posts, weighting each post according to the correlations found. As a more intuitive explanation, the psycholinguistic features are used to calculate the query or key for the self-attention mechanism, while the PLM features are used to calculate the self-attention value. In this way, IAN inherits all the advantages of the graph-based methods. That is, IAN uses the psycholinguistic features as clues to index evidence from the deep semantic features for personality prediction.
As a last point, one of the dilemmas faced by all existing studies is that, in situations where computing resources are limited, only a small portion of an author's posts can be taken as input. To remedy this issue, our IAN framework incorporates a topic clustering method. Thus, the contributions of this study are summarized as follows:
We present an index attention mechanism for personality detection that can be thought of as a PLM-based multi-document classification mechanism. The basic principle is to use prior knowledge to pre-estimate the index score of each document against other documents so as to help aggregate task-specific features as distinct from pre-trained features.
Experiments on two different datasets demonstrate that IAN is a highly effective approach to personality detection. Notably, its performance on the Kaggle dataset is, on average, 13% better than the current state-of-the-art performance in terms of Macro F1 scores.
We visualized the index score matrices in the index attention mechanism as a way to summarize how the working patterns of index attention help facilitate information fusion across different segments. The results provide evidence that using psycholinguistic features to establish inter-document indexes can be quite effective.
In order to conduct personality detection with social media posts, one has to jointly consider many short pieces of disparate text. This is an entirely different task from classifying long tracts of prose. Hence, recently, researchers have proposed several novel ways of enhancing the representation of social media posts by examining the interactions between them. Lynn et al. [34] point out that not all posts are equally important. Based on this idea, they proposed a hierarchical network based entirely on a GRU called SN+Attn. Within this framework, they use message-level attention to learn the weight of each post, while trying to recover high signal messages from noisy data. Similarly, Yang et al. [31] propose a post-order-agnostic encoder named Transformer-MD, which is a modified version of Transformer-XL. Their variant encodes any number of posts through memory tokens that represent previous posts. However, because noisy and scattered semantics are prone to interfere with each other, relying solely on self-attention to refine the representation of social media texts is not particularly wise [25].
The latest method to achieve optimal performance is the graph neural network (GNN), which has been used to model the structural relations between posts. In the graph, the nodes are posts, and the edges represent the similarity between the psycholinguistic features of the content. Generally, pre-trained language models are used to initialize the representations of posts as nodes. Yang et al. [32] tried to inject psycholinguistic knowledge into a heterogeneous graph called TrigNet by associating psycholinguistic category nodes to nodes of posts through word nodes as intermediaries. Zhu et al. [33] proposed CGTN by constructing a second graph of social media posts initialized with psycholinguistic features and employing contrastive learning to determine graph similarity, while Yang et al. [30] developed D-DGCN through a dynamic multi-hop structure that automatically updates inter-post connections. Departing from these graph-based approaches, our study introduces a lightweight attention network enhanced with author-specific topic preference and psycholinguistic knowledge, eliminating the need for complex graph structures.
Recent advances in personality detection have seen a noticeable decline in attention-based and Transformer-based models. This shift is largely attributable to the inherent challenges Transformers face when applied to fragmented and short texts common in social media—specifically, their limited ability to capture user-level patterns from dispersed and heterogeneous linguistic signals. As a result, recent research has increasingly favored graph-based frameworks, which offer a natural means to model latent relationships between posts and facilitate joint learning of user trait representations. These models often incorporate psycholinguistic cues to establish meaningful inter-post connections, as illustrated by the works [33, 32]. While GCN-based methods have demonstrated effectiveness in modeling structural relationships between posts, they face limitations in both robustness and efficiency. These models depend heavily on the quality of graph construction, which can be problematic in the presence of fragmented or noisy user posts where meaningful edges are difficult to define. For instance, methods such as TrigNet and D-DGCN require complex mechanisms (e.g., heterogeneous nodes and dynamic multi-hop edge updates) to infer useful connections, leading to increased computational overhead and implementation complexity.
To address these limitations, we propose a lightweight attention-based framework that revisits the use of self-attention for modeling inter-post dynamics. Rather than relying on fixed graph structures, our method leverages learned attention weights guided by psycholinguistic priors and user-specific topic preferences, allowing for fine-grained control over post importance and interdependencies. In doing so, our approach maintains the relational modeling strength of graph-based methods while improving scalability and reducing computational complexity.
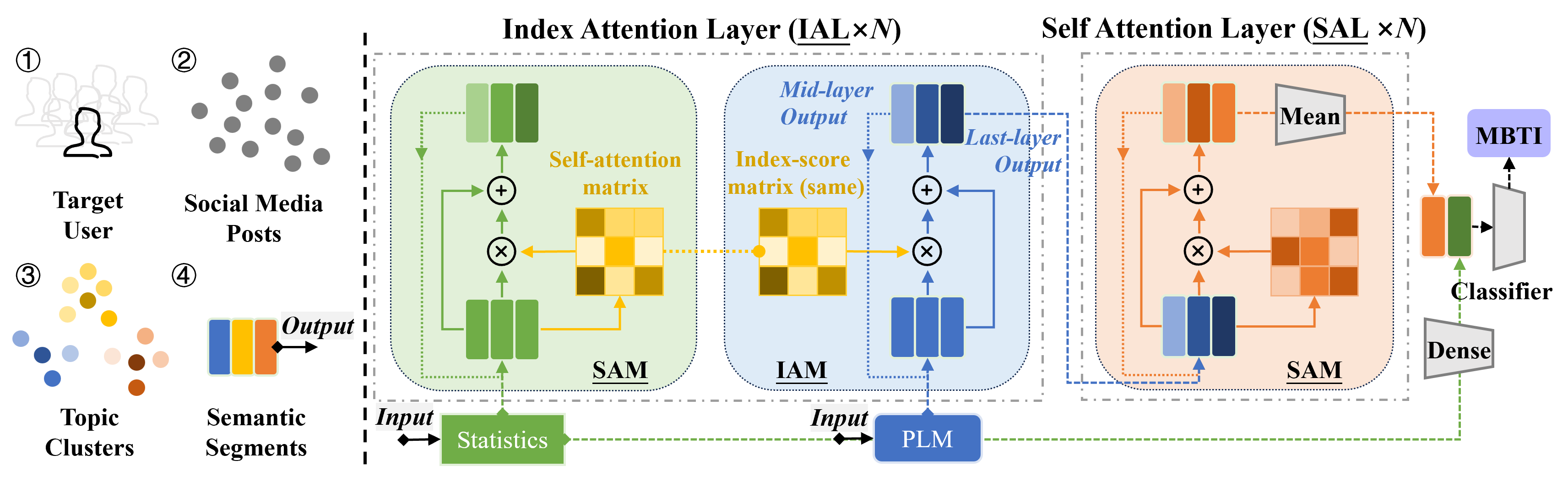
In previous studies, count-based psycholinguistic features are occasionally used as a supplement to deep learning features. Further, a common practice is to directly concatenate the vectors of two features [18, 22, 35]. However, in personality detection, this practice neglects the different natures and potential capabilities of the two types of features.
More specifically, deep semantic information has the ability to reflect an author's thoughts and feelings towards life, along with their behavioral characteristics. According to the American Psychological Association 1: "personality refers to the enduring characteristics and behavior that comprise a person's unique adjustment to life, including major traits, interests, drives, values, self-concept, abilities, and emotional patterns". Pre-trained language models and deep neural networks help us to extract such patterns and link them to specific personality traits. (In this paper, we call them personality patterns.) However, a considerable number of posts consist solely of useless information [36], such as objective descriptions, which can hinder the detection of an author's personality.
By contrast, psycholinguistic features are too shallow to fully depict the personality of an author. But, fortunately, as prior knowledge, they do indicate where the text exposes personality. Notably, psycholinguistic features have found a resurgence in recent studies as a way of enriching the connections between posts. For example, these methods rely on psycholinguistic priors to establish edges between posts, thereby refining post representations within their graph learning frameworks [32, 33]. However, due to the high computational costs of processing so much text or the limited number of samples collected by existing datasets, most extant studies only use a random sample of posts when building graphs for each author. This obviously creates some limitations. First, the edges between posts could be false due to the limited selection of samples alongside the presence of noise. Second, training a GNN with too few posts can be difficult. Hence, in this study, we transformed the posts into semantic segments, which helps to increase the number of interactions between the texts. In addition, our approach is based on index attention, which efficiently harnesses the value of psycholinguistic knowledge when attempting to discover important semantics as evidence for personality detection.
This section describes our proposed attention mechanism – Index Attention – which uses psycholinguistic features for the query and key calculations and deep semantic features for the value calculations. The approach was inspired by the scanning reading technique, where each post is scanned and weighted according to its psycholinguistic features, while the posts' deep semantic features are used to produce the representations. In addition, we recommend clustering the posts to screen for potential content that will help detect personalities. IAN is then built as a stack of index attention mechanisms for the purpose of summarizing the personality patterns scattered through the posts. Figure 2 depicts an overview of our methods.
In social media, an author may have created hundreds or even tens of thousands of posts. Yet, when taking computational efficiency into account, perhaps only a dozen or so can be sampled. Recent studies mostly consider 50-100 random posts, achieving relatively good detection performance from samples of this size [31, 33, 30]. On a different tangent, a series of studies have pointed out the correlations between a user's personality and their topic preferences [11, 37, 38], which inspired us to make a preliminary selection of posts by topics. For example, Gill et al. [39] find that bloggers who are high in 'openness' are likely to express their interests, opinions, and even feelings in the content of topics related to the arts and similar intellectual pursuits. Hence, we wondered whether leveraging a clustering strategy to screen out the topics that the authors are most interested in might lead to high-quality input for a detection model. This process, which is depicted on the left side of Figure 2, is described in more detail as follows:
• The first step is to produce semantic representations of the posts. For this, we use Sentence-BERT (SBERT), which is a modified variant of a pre-trained BERT model [40]. SBERT can generate semantically meaningful sentence embeddings that can then be compared using cosine-similarity or Euclidean distance. Moreover, these measures can be performed extremely efficiently, reducing the effort of clustering of 10,000 sentences from tens of hours down to mere seconds. Notably, accuracy does not suffer during this process.
• Next, topic clustering is performed based on the distance between posts. This is accomplished by HDBSCAN [41], which is a density-based clustering algorithm that can automatically determine the optimal number and shape of the resulting clusters.
• The last step is to draw samples from the largest clusters. Our framework considers the largest clusters, which represent the topics the author is most interested in and, therefore, most likely to talk about. The closest 5-10 posts to the center of each selected cluster are sampled and assembled into a segment of a few hundred words. Thus, the final sample consists of segments of different topics, all with rich semantics.
As mentioned, we drew inspiration for the index attention mechanism from the scanning reading strategy, which is one of the speed reading techniques recommended by colleges and universities 2,3. Scanning means you look only for specific pieces of information, such as a set of keywords, and once you locate a section requiring attention, you slow down and read it more thoroughly. In our attention mechanism, the psycholinguistic features are the specific pieces of information we are looking for, and the deep semantic features are the elements drawn from reading the posts more thoroughly. More specifically, we began with the self-attention mechanism outlined in [25], and modified it such that the query and key calculations are based on the psycholinguistic features, while the value calculations are based on the PLM features.
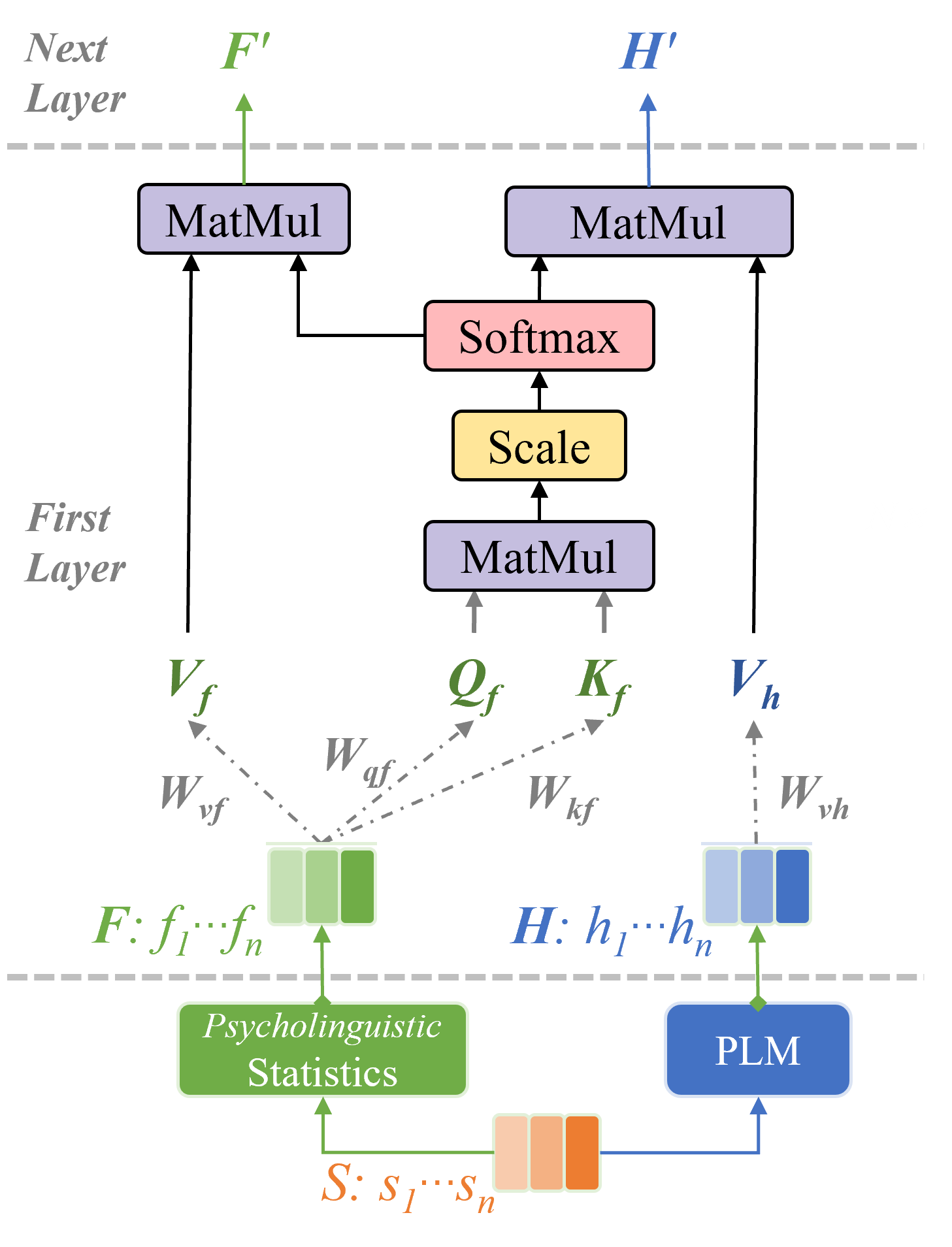
As depicted in Figure 3, psycholinguistic features are extracted from segments , where is a vector of dimensions. PLM features are also extracted from these segments, where is a vector of dimensions. To implement the attention mechanism, four trainable parameter matrices are defined: , , , and . , , have a dimension of (), whereas has a dimension of (, ).
In the index attention mechanism, we first calculate the complete self-attention based on one type of feature, while calculating a sole Value based on another type of feature:
where , , are matrices with dimensions of (), and is a matrix with dimensions of ().
In the standard self-attention mechanism, the attention score matrix is computed using the query and key as follows:
where is a vector of dimensions.
Specifically, the process begins with a matrix multiplication (MatMul) operation between and . This is followed by a scaling operation (Scale) to adjust the values, after which the softmax function (Softmax) is applied to normalize the scaled output, ensuring that the attention weights sum to one.
The resulting attention matrix represents the potential associations between each feature and in the process of identifying personality patterns. This matrix is analogous to the edge values between post nodes introduced by Zhu et al. [33] in their psycholinguistic view graphs.
The core of the index attention mechanism involves using as the index score matrix to apply on via a matrix multiplication (MatMul) operation to generate context (segment)-sensitive deep representations:
In this study, each in is a hidden state encoding a type of personality pattern led by the corresponding segment .
To enhance the model's expressiveness and higher-order relations, a series of index attention layers are stacked together. The output of each layer becomes the PLM input for the next layer. Similarly, in Equation 5 is the output of the self-attention mechanism's attention to the psycholinguistic features, which becomes the psycholinguistic input for the next layer.
This process involves using as the self-attention score matrix to apply on via a matrix multiplication (MatMul) operation.
The self-attention layers in our framework are similar to the Transformer layers in the RoBERTa model [48], in that their purpose is to enhance the representation of each semantic segment from the perspective of purely semantic interaction. Each self-attention layer comprises a single self-attention mechanism—illustrated in Figure 2 and denoted as "SAL" in Figure 1—which follows the design proposed by Vaswani et al. [25].
To accomplish strengthening the context (segment)-related representation of the segment from a purely semantic perspective, from the last index attention layer is updated to according to the following:
where , and are trainable parameter matrices with dimensions of (). This self-attention layer can also be stacked, and the representations of the semantic segments can be averaged to obtain a unique and robust representation of the blog's author:
where refers to the output of the last self-attention layer.
Following prior studies [18, 42], IAN predicts the label for a single dimension of an author's personality. To supplement the final personality prediction, an overall psycholinguistic feature vector, denoted as , is computed based on the content in , similar to previous approaches [18, 35, 43]. The feature vector is subsequently processed through a Dense layer to produce the output , which is then concatenated with . This concatenated representation serves as the input to the classifier, which outputs the logits for a binary prediction:
where denotes the concatenation operation, and contains the raw scores assigned by the classifier for each class.
Next, the Softmax function is applied to the logits to predict the probability of a particular personality class. Specifically, indicates that the personality dimension is positively expressed, while indicates a negative expression. The probability is calculated as follows:
where represents the input segments, and denotes all the parameters of the IAN model except for those related to the calculated statistics in . Here, refers to the raw score output by the classifier for the positive expression of the personality dimension , whereas refers to the raw score for the negative expression. The Softmax function normalizes these logits by exponentiating and dividing by the total sum, yielding a probabilistic distribution over the two possible personality outcomes. A higher probability for suggests stronger positive expression for the dimension, and vice versa for .
Cross entropy loss is used to count the loss over samples:
where refers to the label of the th sample, and refers to the predicted probability of the positive label of the th sample. If some classes in the dataset are severely imbalanced, a weighted cross-entropy loss is used to address the problem:
where is the weight of the class corresponding to , usually set as the ratio of the number of samples in another class to the number in this class.
Following previous studies [31, 30], we validated our methods on two publicly available datasets, Kaggle and Pandora, and employed the Macro-F1 metric to measure performance. The two datasets were randomly divided into 6:2:2 for training, validation, and testing, respectively.
Kaggle is one of the most commonly used datasets for personality detection. It was collected from Twitter 4 by the Personality Caf'e forum. The dataset consists of 8675 groups of tweets and MBTI labels. Each group comprises the last 50 tweets posted by a user. This dataset is available at Kaggle 5.
We have comprehensively considered the composition of psycholinguistic features according to previous studies [18, 22, 33, 35], and built our Statistic tool for Mairesse Features [1], SenticNet Features [44, 45] and NRC Emotion Lexicon Features [46].
We compared IAN with several of the highest performing baselines in recent studies. These included SN+Attn and Transformer-MD as attention-based methods and TrigNet, CGTN, and D-DGCN as graph-based methods. The details of these methods are described in Related Studies.
Tables 1 and 2 present the best results from our experiments for IAN alongside the best results published in the original papers for the baselines. The first block presents the performance of traditional and pre-trained baseline methods, while the second block shows the results of recent attention-based methods, and the third block contains recent graph-based methods. We attempted to stack IAN with more layers but found that detection performance reached its peak when N=3 for Kaggle and N=2 for Pandora. We reason that adding more layers confuses IAN as to which personality pattern representations to retain. Significantly, IAN (N=3) yielded a 13% lead over the existing best result with Kaggle. As for Pandora, IAN achieved comparable performance but is more lightweight and flexible.
| Methods | E/ I | S/ N | T/ F | J/ P | Avg |
| SVM | 53.34 | 47.75 | 76.72 | 63.03 | 60.21 |
| XGBoost | 56.67 | 52.85 | 75.42 | 65.94 | 62.72 |
| BiLSTM | 57.82 | 57.87 | 69.97 | 57.01 | 60.67 |
| BERT | 64.65 | 57.12 | 77.95 | 65.25 | 66.24 |
| SN+Attn | 65.43 | 62.15 | 78.05 | 63.92 | 67.39 |
| Transformer-MD | 66.08 | 69.10 | 79.19 | 67.50 | 70.47 |
| TrigNet | 69.54 | 67.17 | 79.06 | 67.69 | 70.86 |
| D-DGCN | 69.52 | 67.19 | 80.53 | 68.16 | 71.35 |
| CGTN | 71.12 | 70.44 | 80.22 | 72.64 | 73.61 |
| IAN (N=2) | 83.68 | 82.14 | 85.63 | 83.14 | 83.65 |
| IAN (N=3) | 87.92 | 84.48 | 87.16 | 86.89 | 86.61 |
| IAN (N=4) | 83.27 | 80.89 | 85.73 | 85.19 | 83.77 |
| Methods | E/ I | S/ N | T/ F | J/ P | Avg |
| SVM | 44.74 | 46.92 | 64.62 | 56.32 | 53.15 |
| XGBoost | 45.99 | 48.93 | 63.51 | 55.55 | 53.50 |
| BiLSTM | 48.01 | 52.01 | 63.48 | 56.21 | 54.93 |
| BERT | 56.60 | 48.71 | 64.70 | 56.07 | 56.52 |
| SN+Attn | 54.60 | 49.19 | 61.82 | 53.64 | 54.81 |
| Transformer-MD | 55.26 | 58.77 | 69.26 | 60.90 | 61.05 |
| TrigNet | 56.69 | 55.57 | 66.38 | 57.27 | 58.98 |
| D-DGCN | 61.55 | 55.46 | 71.07 | 59.96 | 62.01 |
| IAN(N=2) | 57.85 | 55.23 | 64.61 | 57.84 | 58.88 |
| IAN (N=2,*cluster) | 62.67 | 58.33 | 69.34 | 59.31 | 62.41 |
| IAN (N=3,*cluster) | 57.24 | 56.32 | 63.00 | 57.63 | 58.55 |
To investigate the contribution of sampling versus clustering the topics, we conducted an ablation study using the Pandora dataset, where we removed the clustering step. The Pandora dataset is fairly large, and having a pre-filtering and selecting step on posts would be quite beneficial. Normally, posts would be randomly selected to form segments. However, we see the clustering step does help improve the Macro-F1 (%) score by an average of 3.53%, as shown in Table 2.
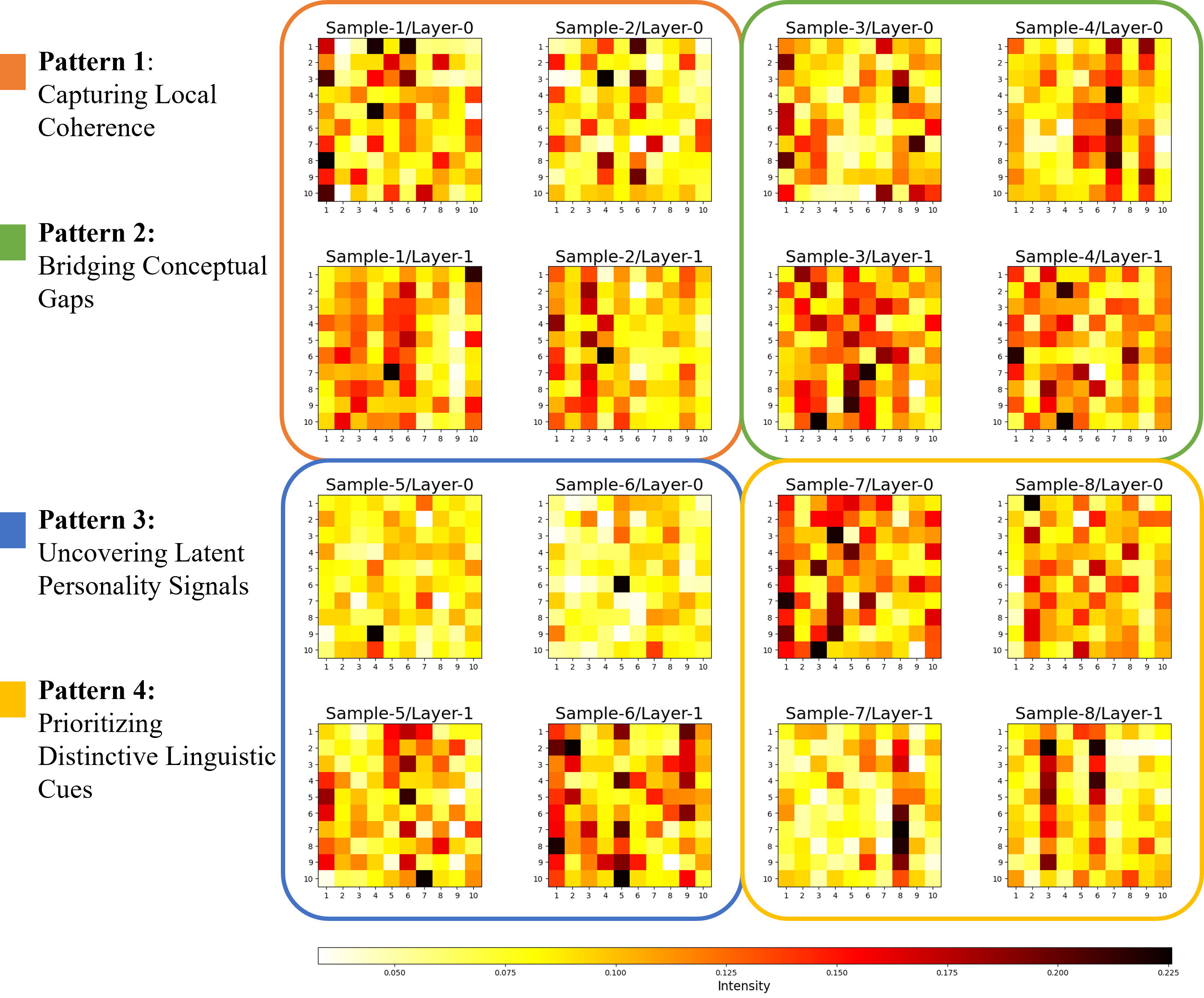
To better understand how the Index Attention Mechanism (IAM) facilitates personality inference, we analyzed attention matrices at different layers and identified four primary attention patterns. Each pattern reveals a distinct way in which personality-related linguistic signals are aggregated across social media posts, which is crucial for addressing the challenge of fragmented and noisy data in personality detection.
These patterns were identified through experiments conducted with IAN (N=2, * cluster) trained on the Pandora dataset (see Table 2), where we visualized the typical index score matrices generated by the attention mechanism in Figure 4. The analysis of these matrices allows us to examine how IAM dynamically integrates psycholinguistic features to enhance personality trait recognition.
Pattern 1: Capturing Local Coherence and Thematic Consistency (Visualized in Samples 1 and 2)
At the first layer of IAM, the attention mechanism predominantly captures local proximity relationships between segments. This means that posts with apparent linguistic or topical similarities tend to receive higher mutual attention scores. However, when enriched with psycholinguistic features, IAM learns to generalize beyond surface similarities and establish deeper semantic connections.
This pattern is crucial for identifying personality traits that are manifested through consistent language use. For example, individuals with a Judging (J) preference in the MBTI framework often demonstrate structured and organized speech patterns across posts, reflecting their inclination toward planning and decisiveness. By detecting such proximities, IAM ensures that semantically related segments reinforce each other, improving personality classification accuracy.
Pattern 2: Bridging Conceptual Gaps (Visualized in Samples 3 and 4)
At the second layer, IAM shifts its focus to reinforcing relationships between segments that initially had weak or indirect associations. This suggests that the mechanism is effectively bridging gaps between posts that might not share direct lexical similarities but are conceptually related.
This pattern is particularly valuable in identifying personality traits that manifest through subtle contextual cues rather than explicit word choices. For example, individuals with an Extraversion (E) preference in the MBTI framework may use varied and context-dependent expressions of social engagement, such as discussing group activities, sharing spontaneous thoughts, or frequently interacting with others online. By learning these indirect associations, IAM improves its ability to detect latent personality signals dispersed across posts.
Pattern 3: Uncovering Latent Personality Signals (Visualized in Samples 5 and 6)
In this pattern, the initial correlations between segments based on surface-level psycholinguistic features appear weak. However, after processing through IAM, these correlations become significantly stronger. This suggests that IAM effectively integrates latent personality indicators that may not be immediately apparent in individual posts.
Many MBTI personality traits, such as Intuition (N), are characterized by abstract, exploratory, and metaphorical language rather than overtly repeated patterns. Intuitive individuals often discuss theoretical concepts, possibilities, and future-oriented ideas, which may appear loosely connected on the surface. This pattern demonstrates IAM's ability to extract deeper personality cues by leveraging psycholinguistic knowledge as an indexing mechanism, ensuring that even weakly correlated segments contribute meaningfully to the final inference.
Pattern 4: Prioritizing Distinctive Linguistic Cues (Visualized in Samples 7 and 8)
In cases where segments initially exhibit high similarity, IAM refines its focus by selectively amplifying key segments with more distinctive psycholinguistic features. These segments receive disproportionately high attention scores, suggesting that IAM prioritizes informative content over redundancy.
This pattern is particularly effective for differentiating between individuals with similar but distinct MBTI traits. For example, both Feeling (F) and Thinking (T) types may express strong opinions, but their linguistic focus differs: Feeling types tend to emphasize empathy, personal values, and emotional impact, whereas Thinking types prioritize logic, objectivity, and analytical reasoning. By prioritizing key segments, IAM ensures that personality inference is based on the most informative and distinguishing linguistic features rather than being skewed by redundant or less relevant content.
The index attention mechanism presented in this paper leverages a set of prior (psycholinguistic) features to facilitate task-specific information fusion across documents—capturing correlations that pre-trained language models may overlook. Centered around each document, this mechanism enables the framework to integrate relevant information from other documents, thereby enhancing the robustness of task-specific representations.
Our implementation is specifically designed for multi-document classification tasks. It uses prior features to predict task-specific relationships between documents and performs information fusion by aggregating effective signals from deep semantics to refine each document's representation. In this study, we applied index attention to exploit the full potential of psycholinguistic knowledge as a clue for indexing and fusing evidence for personality detection from PLM features. We also developed an Index Attention Network (IAN) to detect personality traits from social media posts. IAN seeks to uncover deep semantic evidence through topic preferences, semantic relevance, and psycholinguistic cues. Experimental results on two publicly available datasets demonstrate the effectiveness of our methods.
This study has several noteworthy limitations. First, although our index attention mechanism takes psycholinguistic features as prior knowledge, these features are fixed and do not have the same adaptability as deep neural network features, which can be pre-trained and fine-tuned for downstream tasks. Consequently, psycholinguistic features could be replaced by other feature engineering models, such as a CNN, pre-trained or not, to potentially extract better features than psycholinguistic ones for attention.
The second limitation concerns long text classification tasks. This method is more suitable for text fragments with sparse correlations and less appropriate for tightly contextual, long text classification. The principle of index attention is to filter out irrelevant posts, which may restrict its applicability in certain scenarios.
The third limitation relates to preprocessing. We sampled 100 posts per topic for each blog author, which evidently missed many posts relevant to personality assessment. Extending the index attention mechanism to integrate all sampled posts could enhance the precision of personality recognition.
Future research directions could explore ways to overcome these limitations, such as developing trainable feature extraction methods, improving the ability to handle tightly contextual information, and optimizing sampling strategies to enhance the overall model performance.
The use of computational methods, particularly machine learning and deep learning algorithms, for MBTI personality assessment based on online data raises several ethical concerns. While these advanced techniques offer improved applicability compared to traditional psychological scales, they present challenges in terms of interpretability and ethical implications. The "black box" nature of deep learning algorithms lacks a solid grounding in psychological theory, making their outcomes difficult to explain and potentially hindering the understanding of personality traits within these models. Furthermore, the vast amounts of data required for these algorithms raise significant privacy concerns. The Pandora dataset, for example, which adheres to ethical codes for psychological research, does allow for the use of archival data without individual consent – but only under specific conditions that protect participants from risk and where confidentiality is maintained [29]. Likewise, the Kaggle dataset has been anonymized to protect privacy.
 Copyright © 2025 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2025 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. Chinese Journal of Information Fusion
ISSN: 2998-3371 (Online) | ISSN: 2998-3363 (Print)
Email: [email protected]

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/iece/