

IECE Journal of Image Analysis and Processing
ISSN: 3067-3682 (Online)
Email: [email protected]

The proliferation of smart devices led to the creation of humongous audiovisuals, including photos and videos. Social media platforms such as Facebook, Instagram, and WhatsApp facilitate the easy sharing of the created content with the public [1, 2]. Consequently, celebrities and politicians who have a significant presence on these online platforms became the first targets of "deepfake". The term "deepfake" combines the terms "deep learning," which is a machine learning technology involving multiple layers of processing and "fake" addresses that the content is not real. Deepfakes help users create and synthesize fake audiovisual data [3].
Deepfake refers to the various face and audio modification techniques using deep learning and computer vision. These face modification techniques are further categorized into four types: expression swap, full-face synthesis, attribute manipulation, and identity swap [4]. Among these, identity swap or face swap is the most used deepfake technology that enables the face of a person to be swapped with another. One such example is when an autoencoder-decoder in deep learning created fake pornographic content of a celebrity, validating the misuse of the technology. The people became aware of the identity swap back in 2017 [4].
Deepfakes also introduce forged images, videos, or audio that are difficult to tell apart from the real ones. In 2018, a minute-long video of former US President Barack Obama delivering an iconic hate speech that he never delivered became viral on social media [3]. This deepfake video of Barack Obama was produced by overdubbing his existing footage using a Generative Adversarial Network (GAN) that replicated the precise lip, head, and eye artifacts in the face using 56 hours of sample input movies [1]. Further, a transaction fooled the bank for USD 243,000 with a deepfake audio in 2019 [5, 6, 7]. Thus, deepfakes can cause political or religious tension between different countries, harm the financial market, or deceive the public by spreading false information [8].
Some ethical uses of the deepfake have also emerged in different fields, such as the ability to reshoot movie sequences in the absence of the actor, as witnessed in the Fast & Furious series, which is a prominent example of the media field [9]. Similarly, deepfakes can deliver realistic images of another person lip-syncing with the voice of another, and they can also be used to supply audio to actors who have lost their voices, or a character voice mismatch in the case of artists [10].
Editing tools can also perform different deepfake activities, such as adding, deleting, and replicating images [11]. A new object in an image can be copied using the other image, known as splicing, and an existing object can be deleted by expanding the background image to cover it, called inpainting [12]. Common picture editing software can also perform scaling, rotation, color correction, etc. [3]. However, due to the occurrence of pixel implosion, which causes unnatural-looking visual abnormalities in the skin, face, etc., and pixel density inconsistencies in pictures, a deepfake created by editing tools might be easily spotted in its early stages by human vision. However, because of recent advancements in deep learning technology and free access to vast quantities of data, deepfakes are difficult to recognize using either advanced computer techniques or hands-on human monitoring [3].
Media assets are created from scratch by using auto-encoders and GAN to synthesize the face. A segmentation map, to name a few deep learning techniques to create synthetic visual data. Any image can be synthesized with simple drawings or text descriptions using deep learning techniques. Auditory input also helps to synthesize the person's modifications. Style transfer deep learning technique can create a new image by altering the painting style [13].
In state-of-the-art, different deepfake techniques are used to solve the problem, such as deep learning methods (CNN or RNN), and machine learning algorithms (Support Vector Machine, K Nearest Neighbor, Random Forest, etc.). These techniques are implemented across a variety of different existing datasets. The widely used technique in deep learning is CNN for deepfake detection [14]. Therefore, the IRV2 Hardswish Framework based on deep learning is proposed in this research study. The contribution of our research study is as follows.
To facilitate the detection of subject faces, we commenced by extracting individual frames from videos utilizing the Deep Fake Detection Challenge (DFDC) dataset. This preliminary step enabled us to isolate and process individual frames, setting the stage for subsequent face detection and analysis procedures.
Hardswish activation in residual blocks is used to capture underlying visual data layers effectively. Hardswish offers improved gradient flow, enhanced feature representation, and computational efficiency. This enables our model to better detect subtle deepfake patterns and anomalies.
Extra-dense layers are added to enhance classification accuracy. These layers amplify relevant features, reduce noise, and refine feature representations. This leads to improved deepfake detection performance and robust classification.
We utilized the IRV2-Hardswish model to compute deep features and classify images as real or altered. IRV2's robust architecture and Hardswish activation enable effective feature extraction and detection of subtle deepfake manipulations.
The Deep Fake Detection Challenge (DFDC) dataset is used for experiments. Moreover, cross-validation is performed using two other datasets, i.e., Face Forensics deepfake collections (FF++) and Celeb-F. Results show the effectiveness of the proposed IRV2 Hardswish Framework.
| Ref. | Classifier | Optimizer | Loss function | Dataset | Accuracy | Precision | Recall | AUC |
|---|---|---|---|---|---|---|---|---|
| [15] | CNN | Adam | - | GDWCT, AttGAN, STARGAN, StyleGsAN and StyleGAN2 | 97.72% | - | - | - |
| [16] | CNN | Adam | Similarity aware loss | Faceforensic++, Celeb-DFD v2, Wildfake, DFDC, DFD, DFRs | - | - | - | 83.94% |
| [17] | CNN, SVM+, KNN | Hyper-parameter | - | Yonsei University's Computational Intelligence and Photography Lab Dataset | 89.5% | - | - | - |
| [18] | MTCNN +Random Forest | - | IQA | VGGFace2 CASIA | 99% | - | - | - |
| [19] | CNN | Adam | Loss function | Faceforensic++ | 97.52% | - | - | 99.79% |
| [20] | DADF | AdamW | Loss function | Faceforensic++ | 95.94% | - | - |
The rest of the paper is structured as follows. Section 2 reviews the existing state-of-the-art. Section 3 presents our proposed framework, along with model training and testing parameters. Section 4 provides insight into the experimental results and covers dataset description, preprocessing steps, results, and comparison with existing state-of-the-art. Our research study is concluded in Section 5.
Deepfake detection is an active research area, and several research studies have contributed to accurately performing it. Deepfake detection can be performed using two methods: Convolutional Neural Network (CNN) [15] and Region Convolutional Neural Network (RCNN). In CNN-based deepfake detection, pictures are extracted from a video and fed into the CNN model for training and prediction using spatial information only. On the other hand, RNN-based deepfake detection refers to the series of video frames for training and producing a result, considering both spatial and temporal information into account [16]. Various CNN architectures perform better in distinguishing between GAN-produced pictures and actual audiovisual data [14].
In the subsequent sections, research studies have been classified into two broad categories: 1) image-based deepfake detection and 2) video-based deepfake detection. Only the latest research studies are targeted, in which CNN-based models are used for deepfake detection.
In this section, only those research studies are discussed in which deepfake detection using image-based content is performed, as shown in Table 1.
The model is trained on the following datasets: GDWCT, AttGAN, STARGAN, StyleGAN, and StyleGAN2, and an average of 97% accuracy, precision, and recall is reported. In [18, 19], a critical Forgery Mining (CFM) framework is proposed for forgery detection. It can be flexibly assembled with various backbones to increase the generalization. An aware loss function and Adam optimizer are used to learn global features. The model has been trained on six different datasets and achieved 83.93% AUC.
In [19], CNN is used for deep feature extraction, and the image is supplied to it after passing through the Error Level Analysis (ELA). Passing through ELA is a crucial step as it determines whether the image is modified or not. The resultant features are further classified using Support Vector Machine (SVM) and K-Nearest Neighbour (KNN) by performing hyperparameter optimization to increase the performance. The model achieved the highest accuracy of 89.5%.
Similarly, in [20, 21] forged faces are detected using Image Quality Assessment (IQA) -based features. IQA is significant in the field of multimedia and face forensics. Images are extracted using IQA from the frequency domain and the spatial domain. Subsequently, the images are transferred to the random forest classifier along with the labels of the image during the training phase. The proposed model has achieved the highest 99% accuracy with two standard datasets, VGGFace2 & CASIA.
In another research article [21], the deep learning model is trained to adapt the various face synthesis techniques using fine-grained artifact features. The proposed framework introduced the fake blender module for creating the synthetic images. Moreover, residual-based deepfake detection performs better forgery classification by detecting the residuals from the fake images. The proposed framework gained higher accuracy and AUC FF++ and WildDeepfake datasets. In [22], the Segment Anything Model (SAM) -based Detect Any Deepfake (DADF) framework is proposed to detect face forgery. This framework captures short-range and long-range forgery contexts for fine-tuning. The model was successfully tested on the Faceforensic++ dataset and achieved 95.94% accuracy.
In this section, only those research studies are discussed in which deepfake detection using video-based content is performed. In [23], a Deep Convolutional Neural Network (DCNN) is proposed for facial recognition in videos. DCNN is based on the threshold classifier integrated with the similarity scores of facial recognition among the real videos and the videos displayed.
| Ref. | Classifier | Optimizer | Loss function | Dataset | Accuracy | Precision | Recall | AUC |
|---|---|---|---|---|---|---|---|---|
| [21] | Deep CNN | leave-one-out | ArcFace | Celeb-DF | 97% | 94% | 98% | - |
| [22] | Trans-former+CNN | Stochastic gradient descent optimizer | Log loss | Celeb-DF | - | - | - | 0.97 |
| [23] | CNN+LSTM | Adam | Cross entropy | DFDC and CipLab | 98.27%, 97.81% | 98.24% 97.32% | - | - |
| [24] | CNN+LSTM | Adam | Cross entropy | Forensic, DFDC Celeb-DF | 91.21%, 79.49%, 66.26% | - | - | 0.91, 0.79 0.66 |
| [25] | CNN+LSTM | Nadam | Binary Cross entropy | Celeb-DF | 99.24 | - | - | 99.52 |
Consequently, the highest score is used to classify the video as real or fake. The proposed model is tested on the Celeb-DF dataset and achieves 97% accuracy with an AUC of 0.994. Similarly, local and global features are extracted by combining the vector-concatenated CNN and patch-based positioning to detect all the possible positions using the vision transformer [24]. For distillation, binary cross-entropy is used, and a comparison of the proposed model is made with the SOTA model. The results report that the proposed model outperforms SOTA by 0.006 AUC and 0.013 F1 scores using the DFDC dataset. 2500 fake videos are provided to the proposed model, and 2313 videos are accurately classified as fake. The SOTA model predicted 2276 fake videos among 2500. The model outperforms the SOTA model for the Celeb-DF (v2) dataset by achieving 0.993 AUC and 0.978 F1 score.
In another research study [25], a novel deep learning architecture combining Long Short-Term Memory (LSTM) and CNN is proposed for deepfake detection. The spatial information of CNN is integrated into the temporal information of the LSTM to combat the deepfake. The proposed architecture is implemented using Python and the Kaggle platform on two open-source datasets, DFDC and Ciplab, and achieved 98.27% & 97.81% accuracy, respectively. The error rates are 0.51% and 0.26%, as calculated by the binary cross function. The results show that the LSTM combined with CNN strongly emphasized the importance of the temporal dependencies of deepfake detection for visual data. Similarly, in [26, 27] CNN and LSTM are combined for the deepfake detection of the video frames using different datasets, and their achieved accuracy and AUC values are illustrated in Table 2.
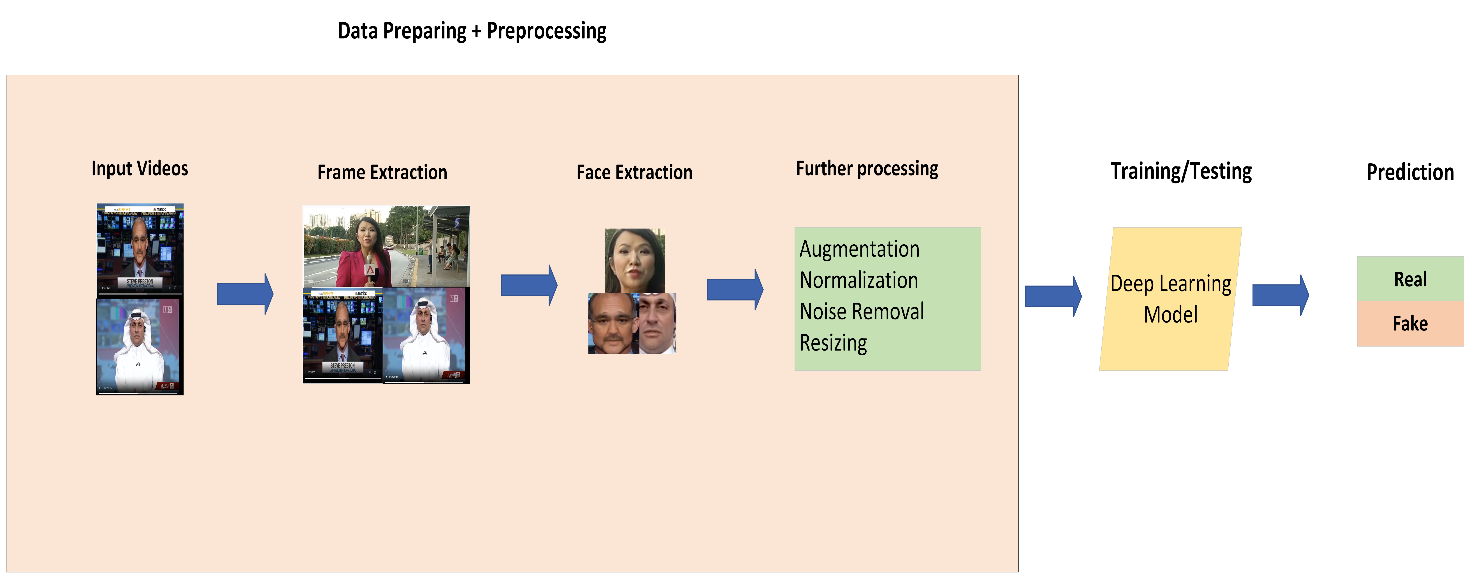
In this research study, a novel IRV2-Hardswish framework is introduced for deepfake detection in videos. The proposed framework consists of the following phases.
Human faces are the prime location where modifications in the deepfake are made. In our proposed framework, human faces are identified from the video frames using the Cascade classifier of the OpenCV tool [3], as shown in Figure 1.
The cascade classifier uses an improved version of the simple classifier to examine the image area to find out whether a face exists in this area or not. Once faces have been identified in the video frames, they may be separated and utilized for additional processing, such as finding visual adjustments [28, 29]. The effectiveness of the face identification procedure can significantly affect how well the final deepfake turns out because false positives or false negatives might result in erroneous or unrealistic results.
Additionally, to maintain the computational complexity of the proposed method, we have only selected 20 frames from all video samples.
After the face extraction, the next step is to calculate the features from the video frames. Inception-Resnet-v2 [29] is modified by adding the Hardswish activation technique and used to perform feature extraction. The Hardswish activation technique is non-linear and capable of adding negative values across the neurons, while feature extraction helps in the identification of complex visual patterns.
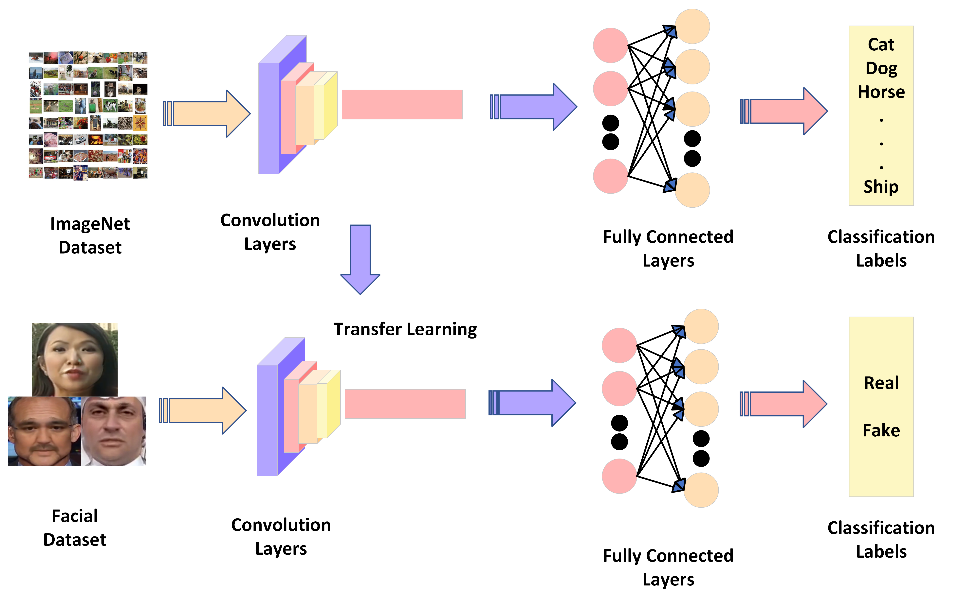
Moreover, the proposed model design also includes additional dense layers and global max pooling in the inception-resnet architecture. The benefit of global max pooling is that it lowers the spatial dimensions of the feature maps to a single value per channel, the number of parameters in the network, and the probability of overfitting. The dense layers enable the model to suggest a representative collection of features for classification. Overall, these adjustments to the Inception-Resnet-v2 model allow it to calculate and extract critical information from the faces in the video frames with more efficiency.
The primary benefit of choosing an inception-resnet architecture is that it has previously been trained on a sizable dataset, like the ImageNet database, and can produce a more accurate collection of image features [29]. The ImageNet collection contains millions of labeled pictures that are used to train neural networks with deep connections for image recognition applications.
Figure 2 provides a graphic illustration of this activity. The ResNet design, on the other hand, makes use of residual connections to allow for the training of far deeper networks. Reusing previously learned characteristics through residual connections makes it simpler for the network to pick up new ones. For deepfake identification applications, this method has been demonstrated to be quite successful, although it can be computationally costly.
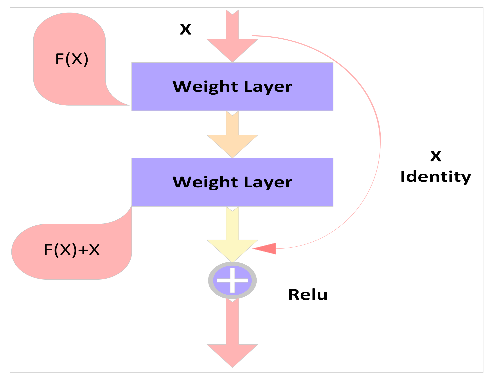
The Residual Block (RB) is the fundamental component of the ResNet model. The ReLU activation function and multiple convolution layers are both included in the RB. It consists of a convenient link, a batch normalization layer, and the stacked layers in charge of residual mapping by using shortcut linkages that carry out identity mapping. The result of the RB can be expressed as in Eq. 1.
where stands in for the input, for the residual function, and for the output of the residual function as illustrated in Figure 3.
The network can learn features at various sizes while still being able to train successfully because of the utilization of residual connections in the Inception blocks. The network, which has 164 layers, was trained using pictures from the enormous ImageNet database as depicted in Figure 4 (a) and (b).
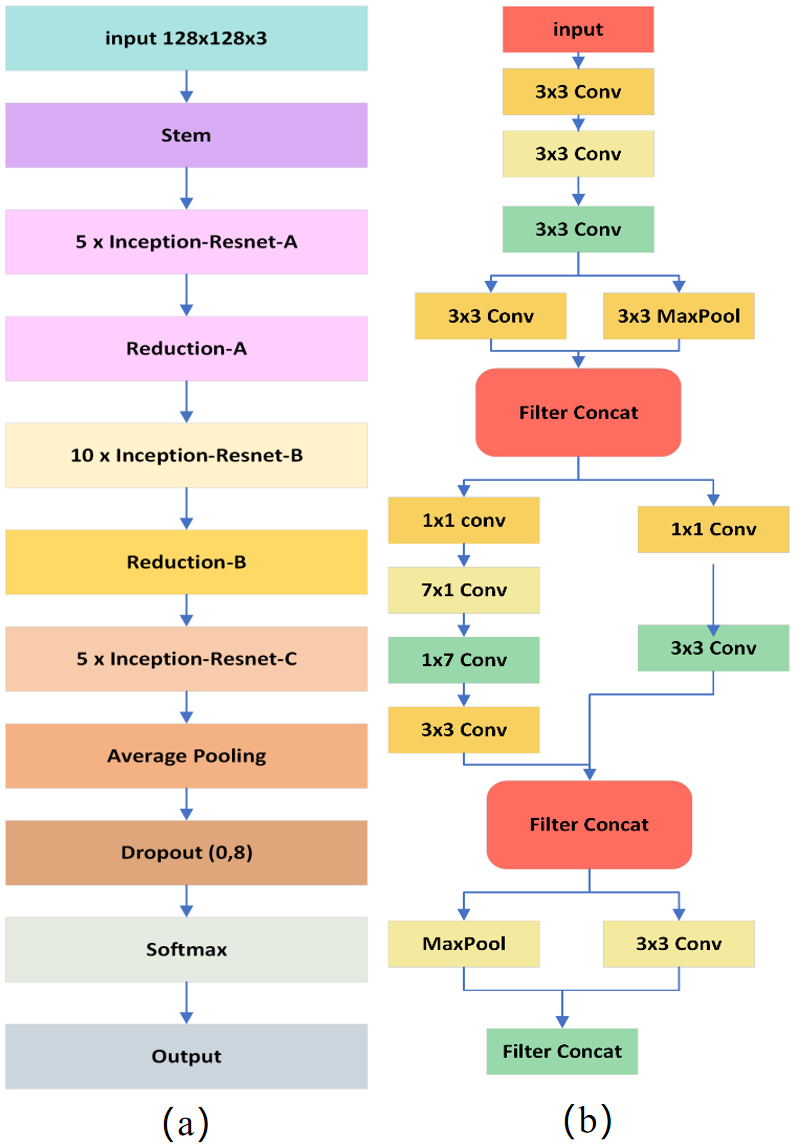
Inception-ResNet v2 is further expanded with batch normalization, bottleneck layers, and an extra classifier to the network. Accuracy and training time both improved by these enhancements. For classification, we introduce transfer learning on the InceptionResnet-v2 network, producing output probabilities for two classes: fake and real. By adding relatively minimal cost to the model design, the additional dense layers improve the model's capacity to learn a trustworthy collection of picture attributes. Once the attributes have been chosen by the additional dense layers, they are sent to the softmax layer to yield the results. The network is trained using shape-related input pictures (128, 128, 3), which were taken from the DFDC dataset.
The model is trained on 30 epochs and produces low validation loss at the end. Hardswish only requires straightforward arithmetic operations, it is computationally efficient when compared to other non-linear activation functions like ReLU. This speeds up computation and makes implementation simpler. Since Hardswish is non-saturating, both high and low input values have no impact on its output. This may assist the model in consolidating more quickly by preventing the gradients from both vanishing or exploding throughout back propagation.
Moreover, Regularization techniques like Hardswish can assist deep learning models from overfitting. Hardswish can aid in ensuring that the model generalizes successfully to new data by limiting how quickly and aggressively it learns [30]. The hardswish activation approach is straightforward by nature, and several studies show that it outperforms the most popular activation methods, such as Sigmoid, Swish, Tanh, and ReLU for images and object identification. Figure 5 provides a graphic representation of swish and other activation techniques.
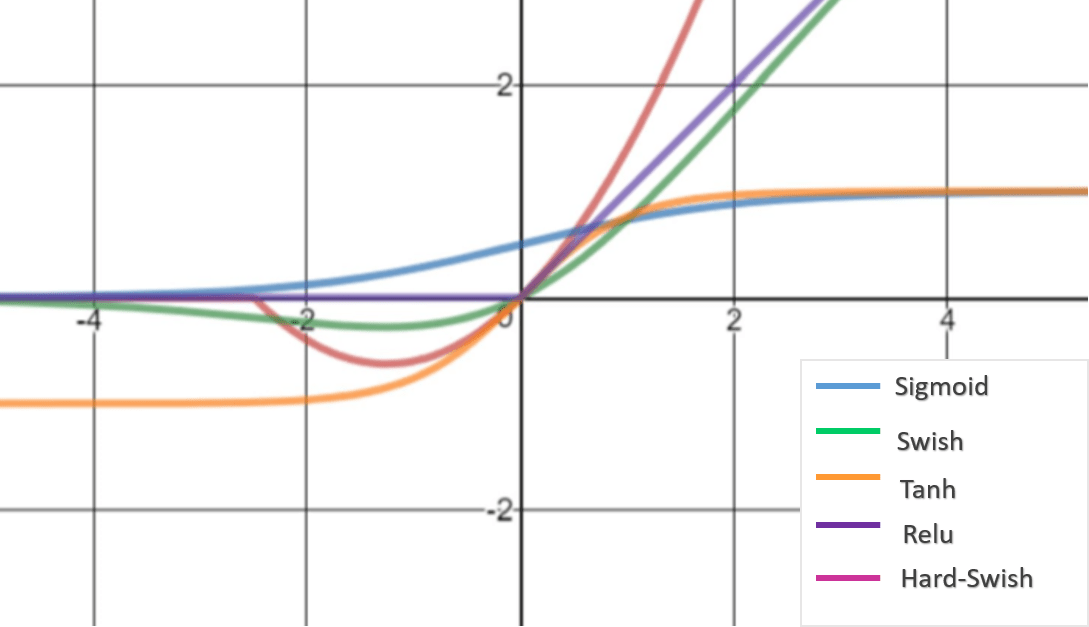
The hardswish mathematical representation is given below in Eq. (2).
where is the input to the activation function.
In this section, the dataset and tools used, and implementation details are highlighted. At the end of this section, results achieved from the proposed models are reported.
The DFDC dataset is selected to experiment with the proposed framework. There are other datasets such as Celeb-DF, Forensic, Forensic++, etc. with forgeries of videos, but we found DFDC to be fairly diversified in terms of the gender, skin tone, age, and color of the actors. Participants were free to record movies with any background of their choice, so DFDC produced visually diverse backgrounds, incorporated a variety of head angles and lighting situations, and increased visual diversity. The DFDC dataset consists of approximately 5,000 clips, including 1,132 actual and 4,118 false ones. The DFDC data are an online dataset that is available to the general public and may be downloaded from the Kaggle competition website [14].
The following tools are used to implement and validate the proposed framework in this research study.
OpenCV: For basic calculations, data retrieval, cleaning, processing, and visualization, the Python Imaging Library (PIL) and OpenCV are used.
Tensor Flow and Keras: Scikit Learn was used to import machine learning models. TensorFlow and Keras were used to construct an artificial neural network.
Matplotlib: Matplotlib was used to plot the different graphs for comparison using Matlab.
In our research, we employ OpenCV, a powerful open-source computer vision library, to extract frames from videos and subsequently detect faces within these frames, as shown in Figure 6. OpenCV provides convenient functionalities, such as the VideoCapture class, which enables us to read video files and extract individual frames efficiently. Once we have extracted frames, we utilize OpenCV's pre-trained Haar cascade classifier for face detection. Haar cascades are a type of machine learning-based object detection algorithm that leverages a cascade of classifiers to identify objects within an image based on their features. Specifically, the Haar cascade classifier for face detection employs a series of rectangular features to detect facial features such as eyes, nose, and mouth. We use the Cascade Classifier class in OpenCV to load the pre-trained Haar cascade XML file and apply it to each frame to detect faces.
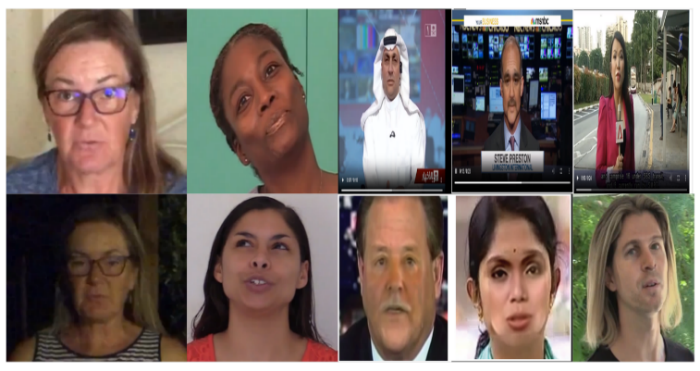
We proceed with additional preprocessing steps to ensure uniformity and standardization of the facial images extracted from the DeepFake Detection Challenge (DFDC) dataset. We resize each detected face image to a standardized size of (128, 128) pixels, a common practice in computer vision tasks to facilitate model training and performance evaluation. This resizing step ensures that all facial images have consistent dimensions, thereby minimizing variations in size that could affect the performance of subsequent machine-learning algorithms.
By creating a structured dataset of resized facial images extracted from the DFDC videos, we establish a foundation for conducting rigorous experiments and analyses aimed at addressing the challenges posed by deepfake content. We leveraged the Inception ResNet-v2 architecture, incorporating a Hardswish activation layer, to tackle the challenge of deepfake detection.
The Inception ResNet-v2 model, renowned for its depth and efficiency in capturing complex features, was chosen for its robustness and superior performance in image classification tasks. By integrating the Hardswish activation layer, known for its non-linearity and efficiency, we aimed to enhance the model's representational power and computational efficiency.
Our experimentation on the DFDC dataset yielded promising results, showcasing the efficacy of the Inception ResNet-v2 model with the Hardswish activation layer. Specifically, we achieved a remarkable accuracy of 98.3% in discerning between genuine and deepfake videos. This high level of accuracy underscores the effectiveness of our proposed approach in accurately identifying manipulated videos, thereby contributing significantly to the ongoing efforts in combating the proliferation of deepfake content across digital platforms. A ROC plot exhibiting AUC is shown in Figure 7.
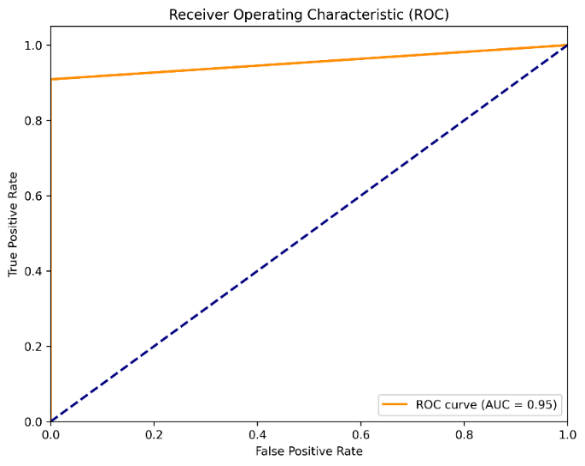
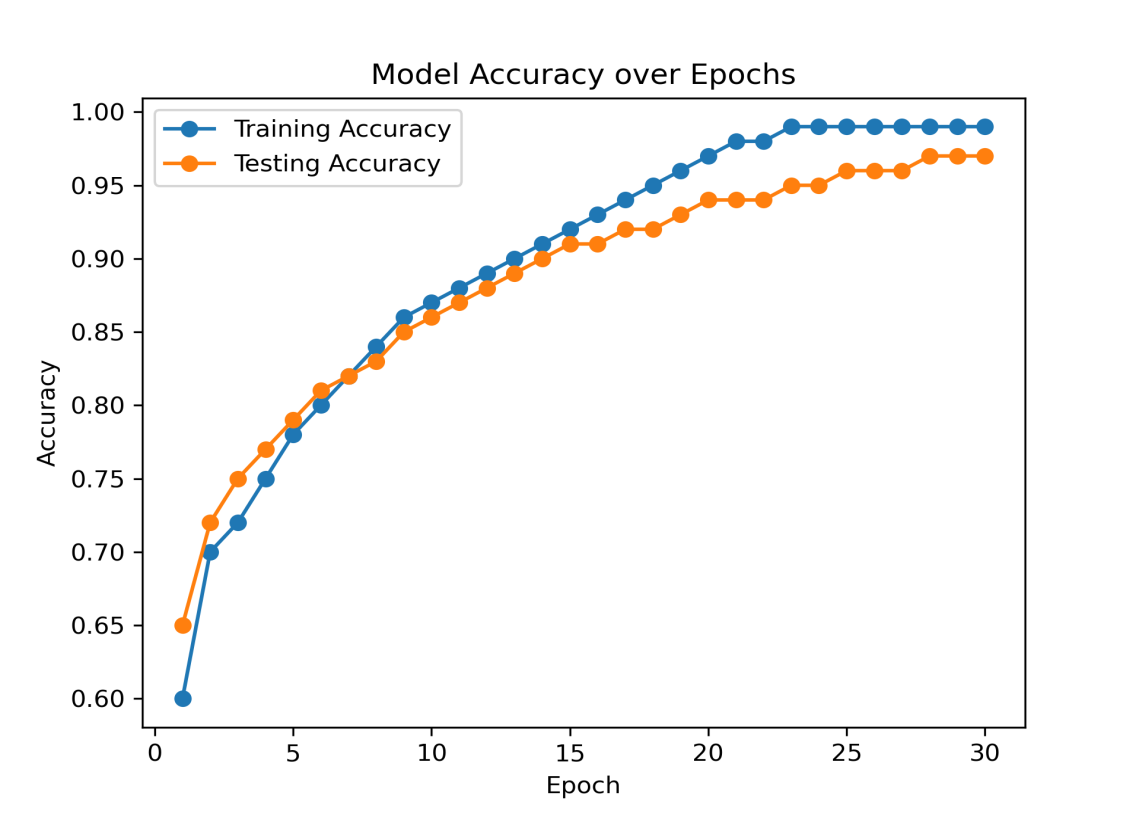
Therefore, a further important statistic for comparison is the classifier's AUC value. The Area Under the Curve (AUC) statistic shows how well the classifier can distinguish between distinct output classes. The stronger the model's capacity to distinguish between the positive and negative classifications, the higher its AUC score. As a result, we have displayed the Receiver Operating Characteristics (ROC) curves and determined the AUC 0.95 score for each of our neural networks as displayed in Figure 8. In Figure 9, the graph shows the accuracy of the proposed model, which improves with increasing epochs as it learns from the data. The blue line represents the accuracy of the training data on which the model learns.
The orange line shows the accuracy of the testing data, which is test data used to evaluate how well the model has learned. Both lines start at a lower accuracy and increase steadily, indicating that the model is learning and improving its accuracy over time. Figure 8 also indicates that the training accuracy (blue line) is mostly higher than the testing accuracy (orange line). This is normal because the model is repeatedly exposed to the training data, making it better at predicting these known examples. Around the 20th epoch, both lines start to level off, meaning the model has learned most of what it can from the data, and additional training does not significantly improve accuracy.
| Ref. | Classifier | Optimizer | Loss function | Dataset | Accuracy | Precision | Recall | AUC | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| [23] |
|
Adam | Cross entropy | DFDC | 98.2 % | 98% | - | - | |||
| [24] |
|
Adam | Cross entropy | DFDC | 79% | - | - |
|
|||
| [31] | Efficient Net | Adam | Binary Cross entropy | Face-forensic++ | 99.2% | 90% | 95% | 94 | |||
| [32] | CNN+GRU | Adam | Binary Cross entropy | DFDC | 92.60% | - | - | - | |||
| [33] |
|
Adam | Binary Cross entropy | DFDC +Custom | 92.61% | - | - | - | |||
| [34] | CNN | Adam | Binary Cross entropy | DFDC | 93.7% | 98% | 97% | - | |||
| Our Model | CNN | Adam | Binary Cross entropy | DFDC | 98.3% | 96% | 96.48% | 0.95 |
Figure 9 shows the error of the model during training and testing, with lower values indicating better performance. The blue line represents the error (or loss) in the training data, while the orange line shows the error in the testing data. Both lines start higher and decrease over time, meaning the proposed model is learning and provides better results at making accurate predictions.
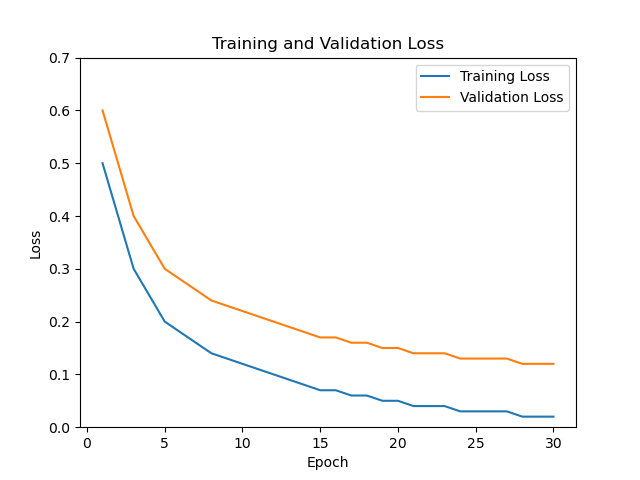
It is analyzed from Figure 9. that the error decreases rapidly, showing that the model quickly learns the basic patterns in the data in the beginning. As training continues, the rate of improvement slows down, indicating that the model is fine-tuning its understanding and making fewer mistakes. The training error (blue line) is consistently lower than the testing error (orange line), which is expected since the proposed model is optimized to perform well on the training data.
In this section, results achieved by the proposed model are compared with the state-of-the-art latest models, mostly using the DFDC dataset, as illustrated in Table 3. Since identifying deepfakes essentially involves classification, several methods are usually compared by determining the evaluation parameters of Precision, Recall, Accuracy, and Area Under Curve (AUC) metrics. Using Inception-ResNet-v2 with Hardswish activation function, our model was able to attain performance values of 98.3% Accuracy, 96.48% Recall, and 96% Precision. With an AUC of 0.95, one of the best state-of-the-art results is attained. In [31], the achieved accuracy is more than the proposed model, however, a dataset other than DFDC is used in this research article.
For cross-validation, an experiment is conducted using FF++ and Celeb-DF datasets to measure the effectiveness of the proposed. The celeb-DF dataset includes 950 edited videos and 475 original videos. The AUC values for the FF++ and Celeb-DF are 70.12% and 65.23%, respectively. When trained on the DFDC dataset, it scored 95% AUC. The results show the effectiveness of the IRV2 hardswish framework when unseen cases of deepfakes are provided, as shown in Table 4.
| Datasets | AUC |
|---|---|
| FF++ | 70.12% |
| Celeb-DF | 65.23% |
| DFDC | 95.00% |
In this paper, a novel deep learning-based architecture is proposed for deepfake detection using a combination of Convolution Neural Network (CNN) and IRV2 Hardswish, and implemented using the DFDC dataset to evaluate its performance. The DFDC dataset comprises approximately 5,000 clips, including 1,132 actual and 4,118 false ones. Our experimental results on the DFDC dataset demonstrate the superiority of the IRV2-Hardswish Framework, achieving state-of-the-art performance in deepfake detection. The synergy of Inception ResNet-v2, CNN, and Hardswish activation enables robust feature extraction and accurate classification, outperforming existing methods. The proposed model achieved an accuracy of 98.3% by outperforming the previous state-of-the-art approaches and distinguishing between real and deepfake videos. Therefore, the fusion of IRV2 hardswish and CNN enables a focus on their respective strengths, potentially yielding an efficient and accurate model. In conclusion, this framework's effectiveness validates its potential for real-world applications, paving the way for reliable deepfake detection solutions.
 Copyright © 2025 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2025 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. 
Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/iece/