
IECE Transactions on Emerging Topics in Artificial Intelligence
ISSN: 3066-1676 (Online) | ISSN: 3066-1668 (Print)
Email: [email protected]

Autonomous driving technology, as a significant breakthrough in today's technological realm, is leading us into a new era of transportation [1]. However, as its development delves deeper, we are gradually becoming aware of the myriad challenges and hurdles that autonomous driving faces. In practical applications, autonomous driving systems must navigate through various complex traffic scenarios and situations, including road conditions, weather conditions, traffic signals, and the behavior of other road users. The complexity of these factors sometimes makes it difficult for autonomous driving systems to make correct decisions, thus sparking concerns about their safety and reliability [2, 3]. Among the plethora of autonomous driving technologies, object detection serves as a crucial component, playing a pivotal role. Object detection systems perceive objects and obstacles in the surrounding environment, providing real-time environmental information and data to autonomous vehicles. Accurately and efficiently detecting and identifying various objects on the road, such as vehicles, pedestrians, and bicycles, is paramount for ensuring the safety and stability of autonomous driving systems. Therefore, research and improvement in object detection technology have become one of the crucial directions in the development of autonomous driving technology [4, 5].
In recent years, with the continuous development of autonomous driving technology, various algorithms have flourished in the field of object detection to meet the demand for precise and efficient object recognition in autonomous driving systems. Firstly, the Yolo series of algorithms is one of the classic representatives in the field of object detection. The Yolo (You Only Look Once) algorithm [6] is renowned for its high speed and concise network structure, capable of detecting and classifying multiple objects in an image in a single forward pass. Its model employs convolutional neural networks (CNNs) for feature extraction and utilizes fully connected layers for object detection [7]. However, due to the issue of inaccurate localization when dealing with small objects and dense scenes, the Yolo algorithm may exhibit lower detection accuracy in certain situations. Secondly, the Faster R-CNN algorithm is another commonly used object detection algorithm [8]. This algorithm extracts candidate object regions by introducing a Region Proposal Network (RPN), followed by object detection and classification through ROI pooling layers and fully connected layers. Faster R-CNN improves detection accuracy compared to the Yolo algorithm but suffers from a complex network structure and relatively slow speed due to its large computational overhead. Additionally, the SSD (Single Shot MultiBox Detector) algorithm predicts object locations and categories simultaneously on feature maps of different scales [9], achieving object detection in a single forward pass. With a simple model structure and fast detection speed, the SSD algorithm is suitable for real-time applications. However, there is still room for improvement in small object detection and object localization accuracy with the SSD algorithm. Lastly, the Mask R-CNN algorithm extends object detection into the realm of semantic segmentation. Building upon Faster R-CNN, this algorithm introduces additional segmentation branches to generate precise object boundaries [8, 10]. While Mask R-CNN [11] excels in object detection and segmentation tasks, its complex network structure and higher computational costs limit its widespread use in practical applications.
The deployment of vehicle detection models also encounters certain challenges. High-precision models often have large-scale architectures, making them difficult to deploy. In practical applications, especially on embedded systems or edge devices with limited resources, deploying these large models becomes even more challenging. Furthermore, even with sufficient computational resources, these models may still have slow inference speeds, affecting their real-time performance [12, 13]. In past research, we have observed a lack of balance between accuracy, speed, and the number of parameters in previous works. Some models may prioritize achieving high accuracy but perform poorly in terms of speed and deployment, while others may have advantages in speed but fall short in accuracy. Therefore, we face the challenge of how to design and train vehicle detection models to maintain high accuracy while having fast inference speeds and fewer parameters [14]. The key to addressing this challenge lies in effective model design and optimization. We can reduce the model's scale and inference costs by exploring lightweight network architectures, quantization methods, and model compression techniques. Additionally, optimizing algorithms and leveraging hardware acceleration can improve the model's inference speed to meet real-time requirements. By considering accuracy, speed, and the number of parameters comprehensively, we can better balance the performance of vehicle detection models and achieve their effective deployment and application in various practical scenarios [15, 16].
In response to the existing challenges, we propose the YOLOv8-Lite solution aimed at enhancing the model's inference speed and reducing its complexity by introducing the lightweight network, FastDet. Additionally, we incorporate the CBAM (Convolutional Block Attention Module) attention mechanism to enhance feature extraction. YOLOv8-Lite is dedicated to addressing the balance between accuracy and efficiency in vehicle detection models, focusing on lightweight architectures and attention-based feature enhancement. Through the design of the FastDet backbone network, we streamline computations while maintaining high detection performance. The integration of the CBAM attention mechanism allows the model to capture richer feature information, thereby improving its ability to accurately detect vehicles in various scenarios. The introduction of this approach represents a significant advancement in achieving a better balance between accuracy, speed, and complexity in vehicle detection models, offering improved feasibility for deployment on resource-constrained devices and enhancing performance in real-world applications.
Here we introduce the three contributions of this paper:
The introduction of the YOLOv8-Lite framework addresses the challenges faced by vehicle detection models by incorporating the lightweight backbone network, FastDet. This framework aims to improve model inference speed and reduce complexity while prioritizing efficiency without compromising accuracy, providing a practical solution for real-time vehicle detection applications.
The integration of the Convolutional Block Attention Module (CBAM) attention mechanism into the feature extraction process further enhances the performance of the YOLOv8-Lite framework. By selectively focusing on informative features, the CBAM attention mechanism improves the model's ability to capture relevant information, thereby achieving more precise vehicle detection across various environmental conditions and scenarios.
This model is more suitable for deployment on resource-constrained devices such as embedded systems or edge devices, expanding its applicability and effectiveness in real-world scenarios.
The application of two-stage object detection algorithms in autonomous driving is a crucial component of the development of autonomous driving technology [17]. First is Fast R-CNN, which achieves end-to-end training of region proposal and object detection by introducing the Region of Interest (RoI) pooling layer, resulting in higher detection accuracy and improved speed. However, it is still constrained by the computational overhead of region proposal generation. Next is Faster R-CNN, which enhances inference speed and efficiency by introducing the Region Proposal Network (RPN) to share convolutional features, yet it still relies on selective search algorithms for region proposal generation, limiting its speed. Further, HyperNet improves localization accuracy by directly predicting bounding box parameters from shared feature maps, effectively handling objects of various scales and aspect ratios, but may increase complexity and computational cost. Mask R-CNN extends Faster R-CNN by adding parallel mask prediction branches, achieving instance segmentation and accurate object localization, albeit at a higher computational cost due to additional mask prediction tasks. Pedestrian FPN (PFN) is specifically designed for pedestrian detection in autonomous driving scenarios, utilizing Feature Pyramid Networks (FPN) to effectively handle pedestrians of various scales and orientations, although it may lead to longer inference times. CRAFT (Cascade R-CNN with Adaptive Feature Fusion) improves detection accuracy by iteratively refining bounding box predictions at multiple stages using a cascade architecture and adaptive feature fusion, albeit potentially requiring longer inference times [18]. In summary, these two-stage object detection algorithms strike a balance between accuracy and speed in autonomous driving, optimizing object localization and instance segmentation, yet they may incur higher computational costs and longer inference times. The selection of suitable algorithms depends on the specific requirements of the autonomous driving system [19].
In the field of autonomous driving, the application of one-stage object detection algorithms has garnered widespread attention [20]. Transformer-based object detection algorithms like DETR have attracted researchers' interest. These algorithms enable end-to-end object detection by introducing attention mechanisms and leveraging global context information, eliminating the need for candidate region generation steps seen in traditional two-stage methods and thus simplifying the process. However, these algorithms often suffer from noticeable performance degradation when dealing with a large number of objects, and they incur higher training and inference costs [21]. Furthermore, the evolution of algorithms from YOLOv5 to YOLOv8 has also been notable. YOLOv5 introduced a lightweight object detection framework that achieved faster inference speed and higher accuracy through improvements in backbone networks and feature extraction methods. YOLOv8 further optimized network structures and training strategies, enhancing detection performance and robustness. Additionally, RetinaNet is another noteworthy algorithm that addresses class imbalance issues by introducing focal loss but suffers from slower inference speeds. Similarly, SSD, known for its simple and efficient design, holds a significant position in the object detection domain; however, its performance diminishes when detecting small objects or objects with different aspect ratios. In summary, these algorithms have their own strengths and weaknesses in terms of detection performance, speed, and applicability, thus requiring comprehensive consideration based on specific application requirements and scene constraints when selecting the appropriate algorithm [22].
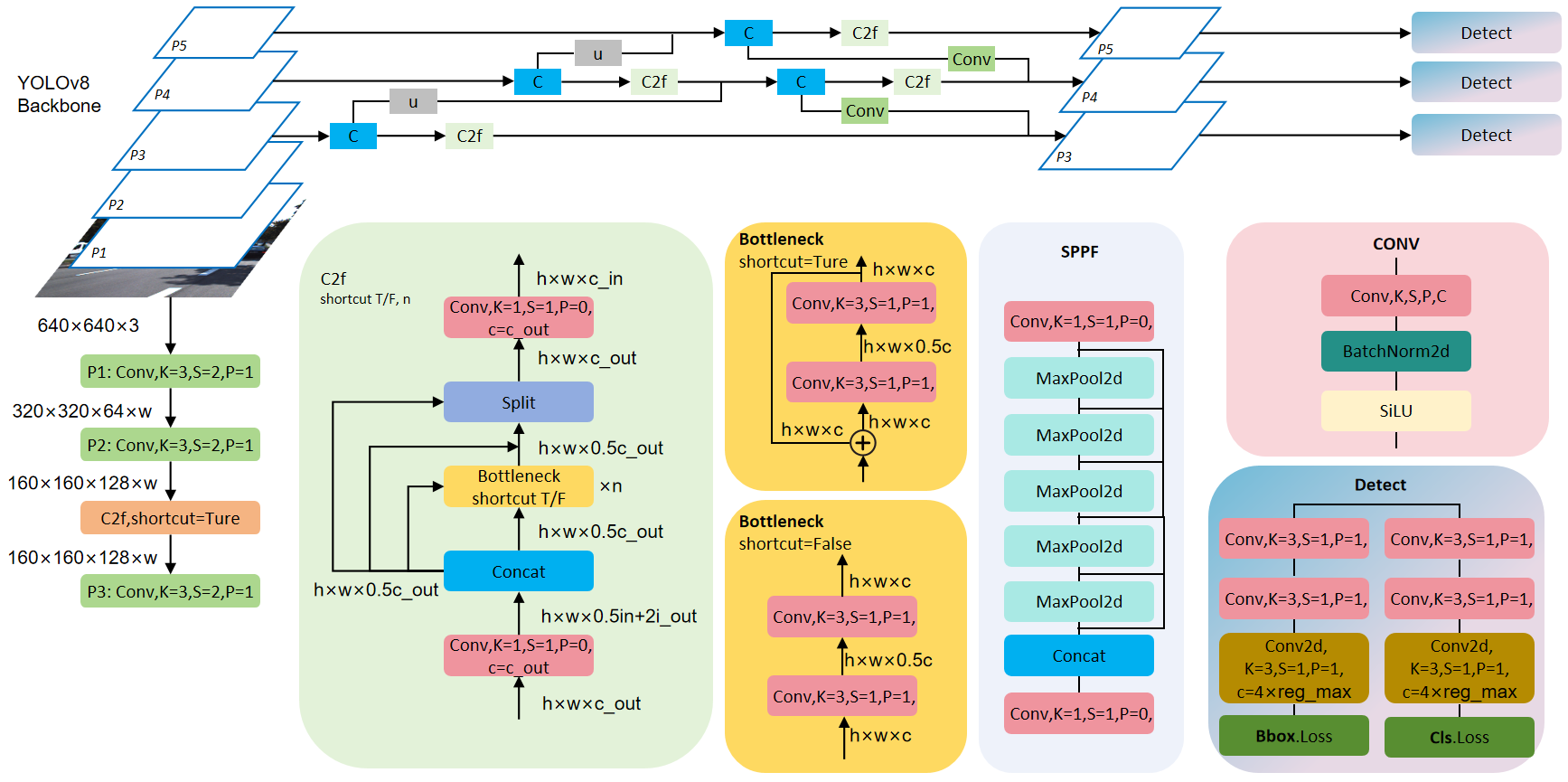
YOLOv8 is the latest advancement in the You Only Look Once (YOLO) series, boasting outstanding performance and innovative design [23]. This model enhances the accuracy and efficiency of object detection by introducing a series of new techniques and optimizations. The network architecture of YOLOv8 is illustrated in Figure 1.
The improvements in YOLOv8 can be attributed to several aspects:
YOLOv8 draws inspiration from the design philosophy of YOLOv7 ELAN for its backbone network and Neck part. It replaces the C3 structure of YOLOv5 with a richer C2f structure and fine-tunes different channel numbers for models of different scales. These refinements and optimizations significantly enhance the model's performance and make it more suitable for various complex scenarios.
Compared to YOLOv5, YOLOv8 introduces significant changes to its Head part. It adopts the mainstream decoupled head structure, separating classification and detection heads. Additionally, it transitions from an Anchor-Based approach to an Anchor-Free approach, further improving the model's detection accuracy and robustness.
To better optimize the model's performance, we employ the TaskAlignedAssigner positive sample allocation strategy and introduce Distribution Focal Loss. These new loss computation schemes effectively enhance the model's training stability and convergence speed, further boosting its performance.
Through these innovative designs and optimization strategies, YOLOv8 has made significant advancements in the field of object detection, providing more reliable and efficient solutions for applications such as autonomous driving.
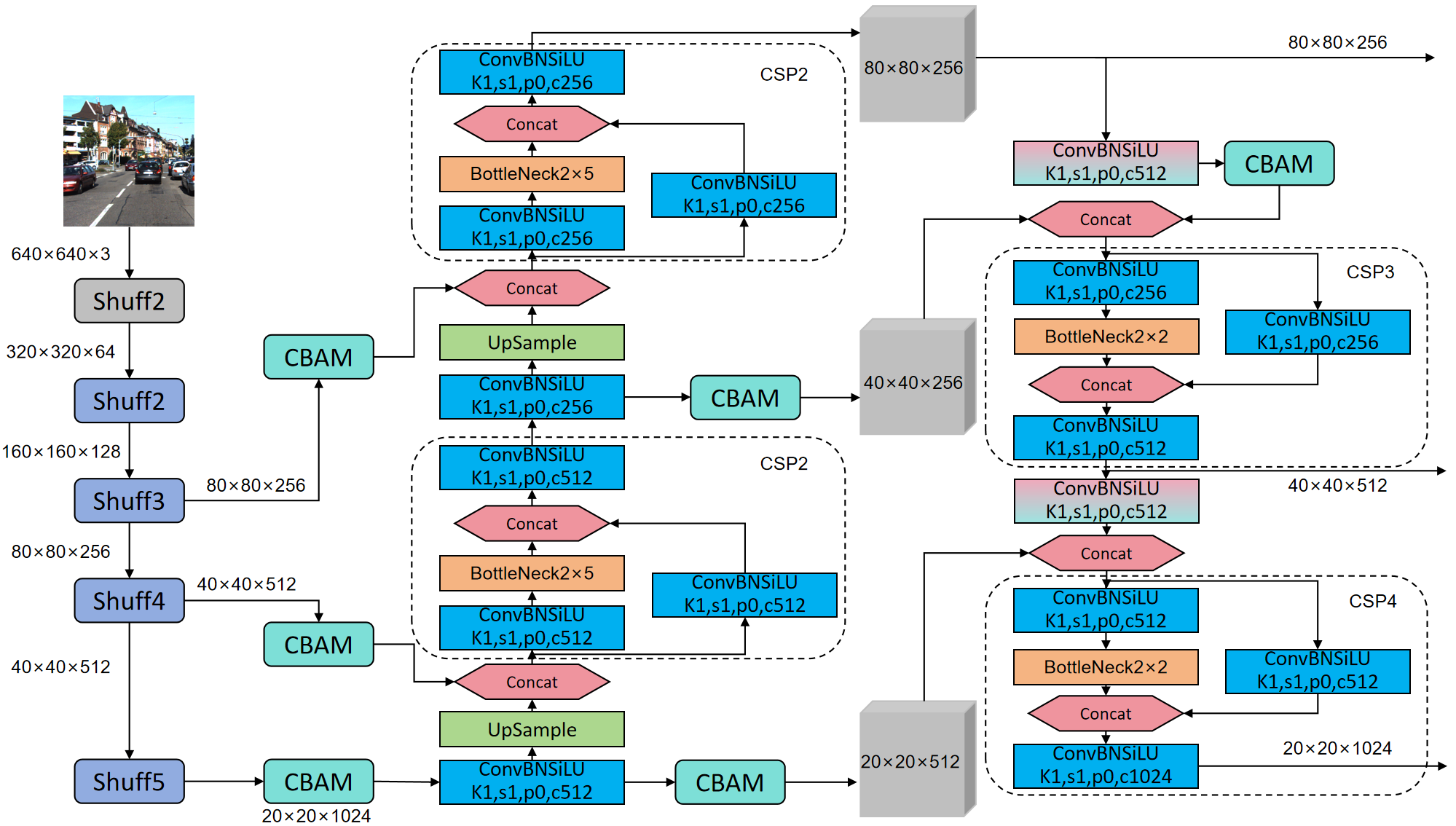
Our overall network architecture takes into account the computational resource constraints of devices in scenarios such as autonomous driving. Therefore, we opted for a lightweight network model called YOLOv8-Lite. As shown in Figure 2, YOLOv8-Lite is based on the YOLOv8 framework and achieves efficient object detection through simplified design and optimized computation. Recognizing the demands for real-time performance and efficiency, we avoided large network structures like CSPDarkNet53 and instead adopted our proposed FastDet structure, which simplifies network complexity and is better suited to the computational resources of edge devices. Additionally, we introduced the TFPN (Top-Down Feature Pyramid Network) pyramid structure to address information loss during feature fusion. The TFPN structure effectively merges feature maps from different levels, enhancing the network's detection capability across different scales while reducing information loss. This pyramid structure design allows for a more comprehensive understanding of input images, thereby improving object detection accuracy. Furthermore, we introduced the CBAM (Convolutional Block Attention Module) mechanism to further enhance the network's representation capability. The CBAM mechanism adaptively adjusts attention within feature maps, enabling the network to focus more accurately on important target areas, thereby improving object detection performance. The introduction of this mechanism enhances the network's robustness in handling complex scenarios and occlusions, making it more suitable for practical applications such as autonomous driving.
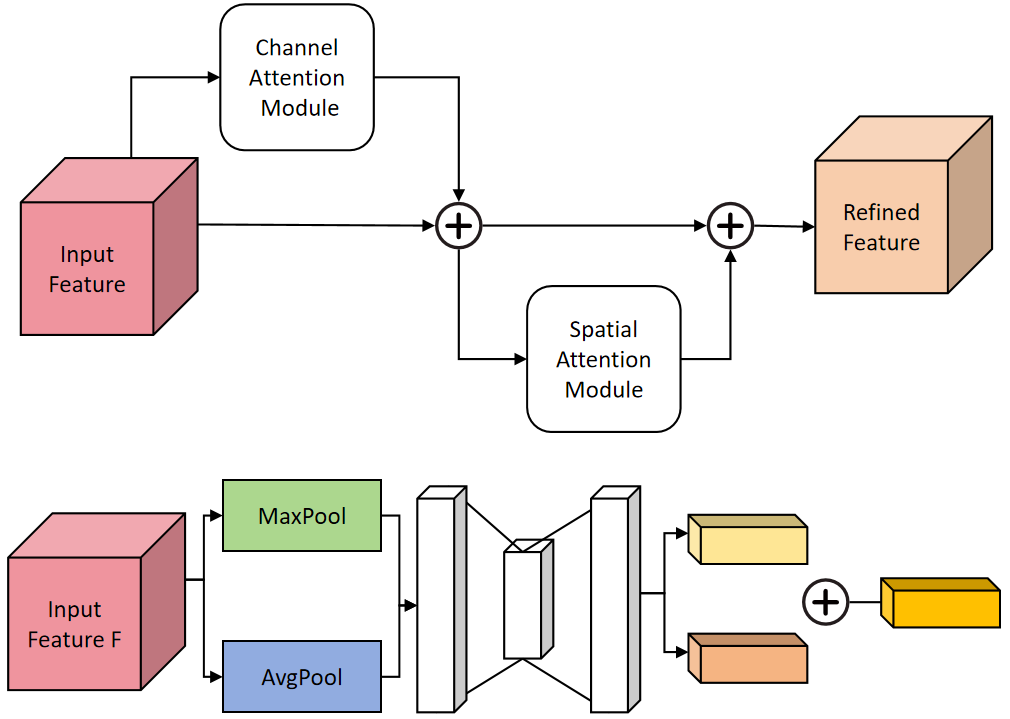
In the field of deep learning, attention mechanisms play a crucial role in allowing models to focus on relevant information while filtering out irrelevant details [24]. CBAM (Convolutional Block Attention Module) is a popular attention mechanism designed to enhance feature representations in deep neural networks. It consists of two complementary sub-modules: the Channel Attention Module (CAM) and the Spatial Attention Module (SAM). CAM recalibrates feature maps across channels to emphasize informative features, while SAM recalibrates feature maps spatially to capture contextual information. We introduced the CBAM attention module into the Feature Pyramid Network (FPN) to strengthen the feature extraction network, effectively extracting crucial features from the feature maps and improving the model's accuracy. Specifically, within the FPN architecture, we incorporated 6 ECA attention blocks. These attention blocks dynamically adjust the importance of features across channel and spatial dimensions, enabling the model to focus on relevant regions and enhance performance. The network architecture of the CBAM is depicted in Figure 3.
In the following equations, we introduce the key mathematical formulations of CBAM:
The Channel Attention Map is computed as the sigmoid activation of the average channel-wise feature responses.
where is the channel attention map. and are the height and width of the feature map, respectively. is the feature map at position . represents the weights used for channel-wise convolution. denotes the sigmoid activation function.
The Spatial Attention Map is computed similarly, capturing spatial dependencies across the feature map.
where is the spatial attention map. is the number of channels in the feature map. represents the -th channel of the feature map. represents the weights used for spatial-wise convolution.
The Output Feature Map is obtained by combining the channel and spatial attention maps element-wise with the original feature map , enhancing the model's ability to focus on relevant regions.
where is the output feature map. denotes element-wise multiplication.
The Global Average Pooling operation computes the average value of each channel in the feature map , providing a global context for the spatial features.
where represents the global average pooling operation applied to the feature map .
The Multi-Layer Perceptron (MLP) is applied to the input feature map to capture more complex patterns and relationships. Here, and represent the weights of the MLP layers.
where denotes the multi-layer perceptron (MLP) applied to the input feature map . and represent the weights of the MLP layers.
Our TFPN network architecture is uniquely designed for object detection tasks, aiming to fully leverage the information from feature maps at different scales [25]. Firstly, we enhance the output feature maps of Dark3, Dark4, and Dark5 in the backbone network, which contain target information at different scales. Next, we employ a top-down upsampling approach, using bilinear interpolation to resize the feature maps from deeper layers to match the sizes of shallower feature maps, facilitating feature fusion. This method ensures the effective fusion of feature maps at different levels and the comprehensive utilization of the information they carry. Subsequently, we perform bottom-up convolution or pooling operations to gradually downsample the feature maps from shallower to deeper layers, extracting more semantic information. This bidirectional feature extraction process helps the model better understand the semantic content of images, thereby improving the accuracy and robustness of object detection. The network architecture of TFPN is illustrated in Figure 4.
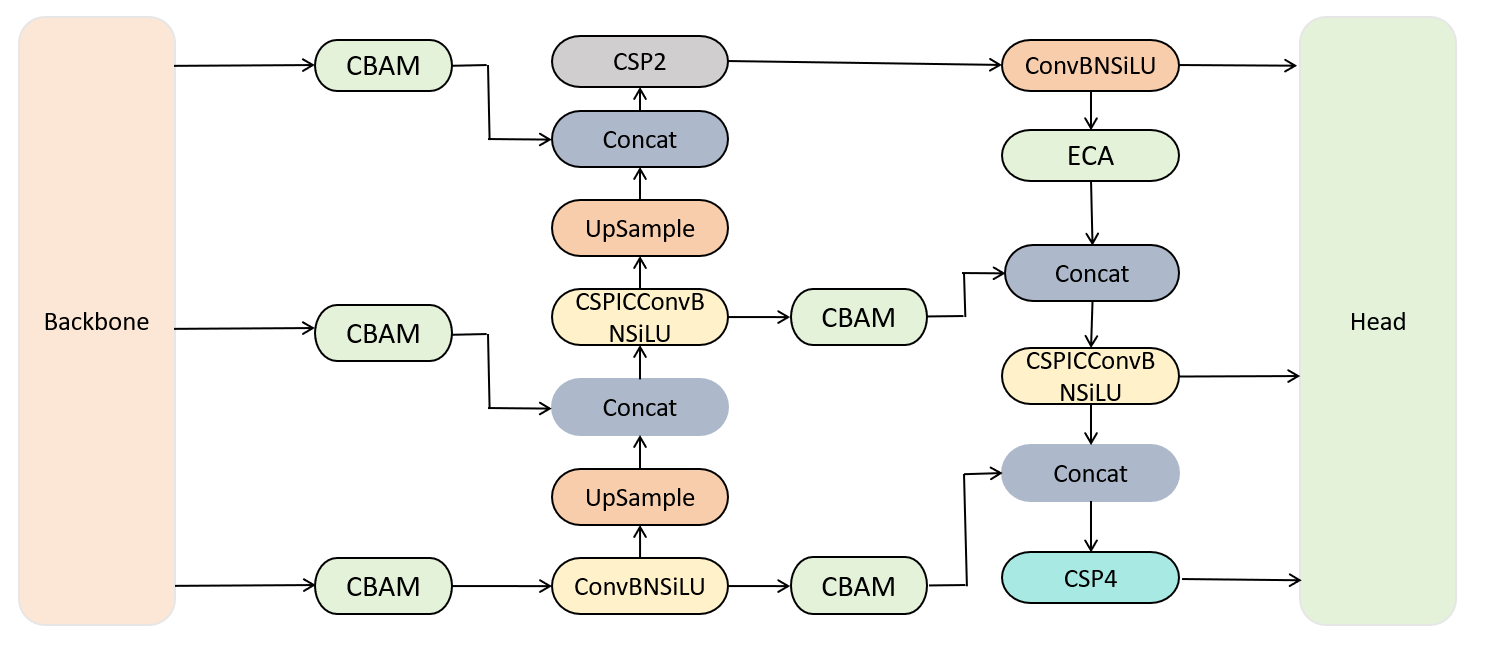
Below, we explain the main mathematical derivation formulas of TFPN:
where is the feature map at level , is the feature map at level , is the weight matrix for convolution at level , is the feature map after bottom up processing at level , is the bias term at level .
where is the rectified linear unit activation function.
where is the weight matrix for convolution at level , is the feature map at level , denotes the convolution operation.
where is the upsampled feature map from level , denotes the bilinear interpolation operation.
where is the feature map at the first level, is the input image or feature map, denotes the convolution and pooling operations.
In the CSPDarkNet53 structure, the Dark module serves as a critical feature extraction module designed to extract image features for subsequent tasks. Adopting a deep residual structure, this module utilizes a series of convolutional and pooling layers to extract and abstract features from input images [26]. While the Dark module has been designed with lightweight principles in mind, it may still have some limitations under certain circumstances. For instance, when processing large-scale feature maps, the Dark module may require significant computational resources, resulting in slower inference speeds. Particularly in scenarios where real-time performance is crucial, the performance limitations of the Dark module may restrict the model's applicability. Therefore, despite making progress in lightweight design, further optimization and improvement are still needed to enhance its performance in fast object detection tasks.
We introduce the innovative FastDet structure, designed based on lightweight principles, to improve the inference speed and accuracy of object detection models. This structure begins with a simple 1 × 1 convolution operation, followed by the Fast module performing channel shuffling, dividing the feature map into two segments along the feature channels. This design enables the model to more efficiently extract and utilize feature information, significantly boosting inference speed while maintaining accuracy. Figure 5 illustrates the structures of Dark and FastDet, where the Dark module consists of multiple convolutional layers and pooling layers, forming a deep residual network for feature extraction. In contrast, the FastDet structure employs a more simplified approach, with a simpler architecture.
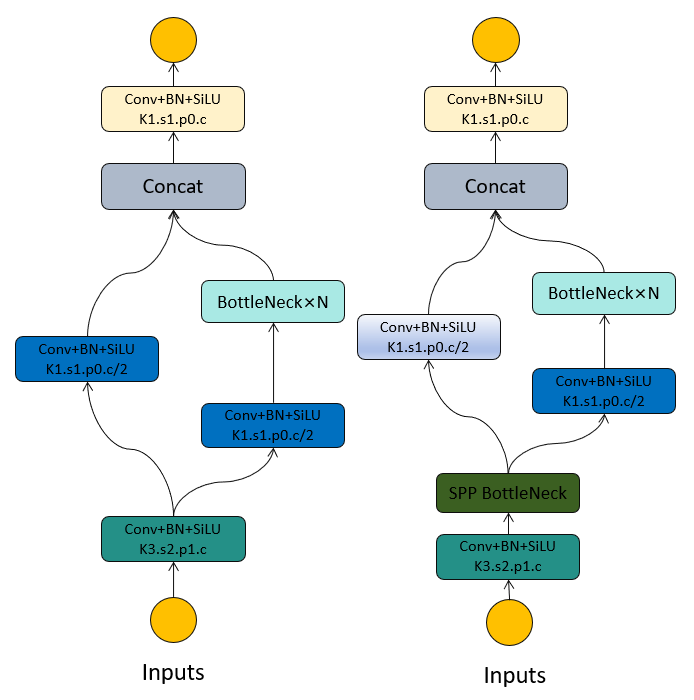
Below, we explain the main mathematical derivation formulas of FastDet:
where is the output feature map, is the weight matrix, is the input feature map, is the bias vector.
where is the output feature map after channel shuffling, denotes the channel shuffling operation.
where and are the output feature maps split along the channel dimension, denotes the feature map splitting operation.
where is the output feature map after convolution, denotes the convolution operation.
where is the output feature map after pooling, denotes the pooling operation.
To evaluate the performance of our proposed method in various scenarios, we selected two representative datasets: NEXET and the KITTI dataset.
The NEXET dataset is a large-scale video dataset widely used in the field of autonomous driving. It covers various urban streets [27], highways, and rural roads under different weather conditions and road conditions. The dataset provides high-resolution video clips along with rich annotation information, including bounding boxes, class labels, and motion trajectories of vehicles. This makes the NEXET dataset an ideal choice for studying and evaluating object detection algorithms.
The KITTI dataset is a classic dataset for autonomous driving [28], jointly released by the Karlsruhe Institute of Technology (KIT) and Toyota. It contains images, point clouds [29], and pose information collected from sensors mounted on vehicles. The dataset covers various tasks in urban and suburban road scenes, including object detection, object tracking, and stereo vision. Annotation information in the KITTI dataset includes bounding boxes and class labels for objects such as vehicles, pedestrians, and bicycles. Due to its realistic scenes and rich annotation information, the KITTI dataset is widely used for the development and evaluation of autonomous driving algorithms.
As shown in Table 1, our experimental setup is presented.
| Parameter | Configuration |
|---|---|
| CPU | Intel Core i7-12700KF |
| GPU | NVIDIA GeForce RTX 4090 (24 GB) |
| CUDA version | CUDA 11.6 |
| Python version | Python 3.9.13 |
| Deep learning framework | Pytorch 2.0.0 |
| Operating system | Ubuntu 22.04.2 |
We selected a total of 53,460 images from the NEXET dataset. According to the partition criteria of 70% for training, 20% for validation, and 10% for testing, the training set comprises 37,422 images, the validation set comprises 10,692 images, and the test set comprises 5,346 images. Similarly, we selected 37,586 images from the KITTI dataset, with the training set containing 26,310 images, the validation set containing 7,517 images, and the test set containing 3,759 images.The specific results are shown in Table 2.
| Dataset | Training Set | Validation Set | Test Set |
|---|---|---|---|
| NEXET | 37422 | 10692 | 5346 |
| KITTI | 26310 | 7517 | 3759 |
During the data cleaning phase, we first identify and remove outliers and noise from the image data. Next, we assess the quality of the images and eliminate those with poor quality to ensure consistency and reliability of the data. Additionally, we perform standardization procedures on the images, such as resizing and background removal, to prepare a clean dataset for model training.
To increase the diversity and richness of the dataset, we employed data augmentation techniques to augment the image data. Data augmentation includes operations such as random rotation, flipping, cropping, and brightness adjustment to generate additional training samples, thereby enhancing the model's generalization ability and robustness.
Our training settings for the YOLOv8-Lite model took into account the practical requirements of the autonomous driving domain. We opted for a lightweight model suitable for edge devices and employed representative parameter configurations during training. As shown in Table 3, the learning rate was set to 0.001, and we utilized the Adam optimizer to enhance convergence speed and accuracy. Given the high real-time demands of autonomous driving tasks, we set the batch size to 640 to improve training efficiency. Additionally, to prevent model overfitting, we applied a small weight decay value of 0.001. The training epochs were set to 300 to ensure the model adequately learned the features and patterns within the dataset. Ultimately, our YOLOv8-Lite model, with these parameters, consisted of 4,385,523 parameters and 252 layers, providing an efficient and reliable solution for object detection tasks in the autonomous driving scenario.
| Parameter | Value |
|---|---|
| Learning Rate | 0.001 |
| Optimizer | Adam |
| Batch Size | 640 |
| Weight Decay | 0.001 |
| Training Epochs | 300 |
| Model Parameters | 4,385,523 |
| Number of Layers | 252 |
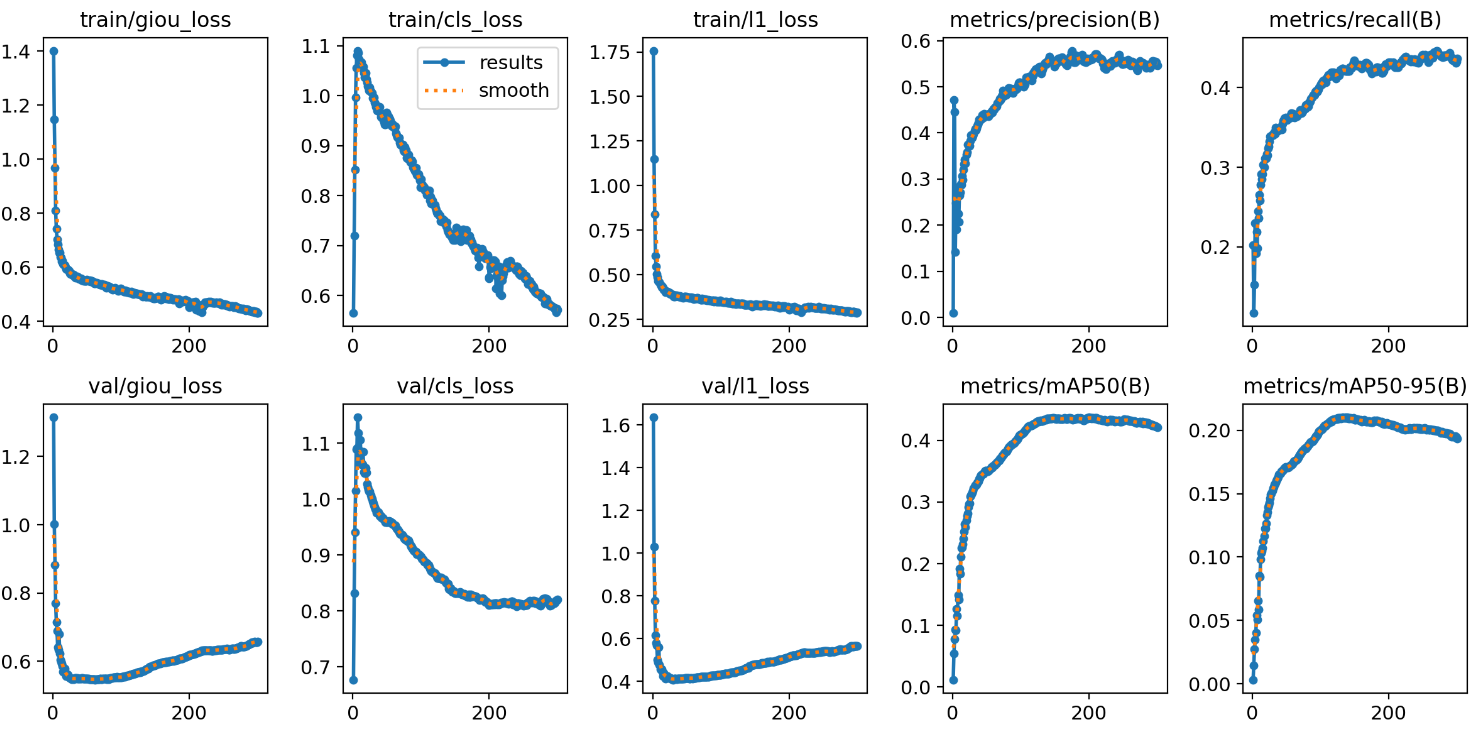
During the training process, we closely monitored the changes in various metrics, which are crucial for evaluating model performance and training progress. Figure 6 illustrates the variations in bounding box loss, confidence loss, and class loss. Analyzing these loss curves enables us to gain a clearer understanding of the model's performance during training. Specifically, our model demonstrated outstanding performance, with gradual decreases in bounding box loss, confidence loss, and class loss, indicating a progressive improvement in the accuracy and precision of the model for object detection tasks. Our model can effectively detect objects in images and accurately classify and localize them. This steady improvement validates the effectiveness of our training process and the robustness of the model. Our model exhibited excellent performance on both the NEXET and KITTI datasets, providing a reliable solution for object detection tasks in practical applications such as autonomous driving.
Algorithm 1 shows the training process of our network.
Training dataset: NEXET and KITTI
Trained YOLOv8-Lite network
Initialize YOLOv8-Lite network parameters randomly
Set learning rate , batch size , and number of epochs
for to do
for to do
Sample a mini-batch of size from the training dataset
Forward pass: Compute predicted bounding boxes and confidence scores
Compute loss function using ground truth bounding boxes
Backward pass: Update network parameters using gradient descent
end for
Evaluate precision and [email protected] on the validation set
if Validation [email protected] has improved then
Save current model parameters
end if
end for
The experiment adopts the following evaluation metrics to comprehensively assess the model's performance:
| KITTI | NEXET | |||||||
|---|---|---|---|---|---|---|---|---|
| Methods | Precision | F1 Score | [email protected] | FPS | Precision | F1 Score | [email protected] | FPS |
| SSD [9] | 58.37 | 54.09 | 56.29 | 18 | 56.19 | 51.86 | 53.09 | 9 |
| Faster-RCNN[20] | 64.16 | 52.07 | 49.09 | 20 | 61.90 | 51.42 | 47.88 | 15 |
| FCOS [32] | 71.58 | 52.62 | 59.82 | 21 | 68.86 | 49.98 | 57.63 | 19 |
| YOLOv5n [30] | 66.13 | 64.56 | 60.89 | 42 | 63.02 | 61.20 | 58.67 | 39 |
| YOLOv7-tiny [31] | 67.92 | 62.62 | 65.36 | 62 | 65.69 | 59.91 | 63.16 | 60 |
| YOLOv8n [19] | 70.82 | 66.63 | 66.35 | 57 | 68.58 | 64.36 | 64.22 | 54 |
| Ours | 76.72 | 74.62 | 75.32 | 85 | 74.52 | 71.82 | 73.12 | 72 |
Accuracy: Evaluates the ratio of accurately classified instances among the total instances.
where are the number of correctly predicted positive instances, are the number of correctly predicted negative instances, and is the total number of instances.
Recall: Gauges the ratio of accurately identified true positive instances by the model among all genuine positive instances.
where are the number of correctly predicted positive instances, and are the number of incorrectly predicted negative instances. Recall measures the proportion of true positive instances correctly identified by the model among all actual positive instances.
Precision: Assesses the ratio of accurately predicted true positive instances among all instances flagged as positive by the model.
where are the number of correctly predicted positive instances, and are the number of incorrectly predicted positive instances. Precision measures the proportion of true positive instances among all instances predicted as positive by the model.
F1 Score: Represents the harmonic average of precision and recall, ensuring equilibrium between them.
F1 Score is the harmonic mean of precision and recall, providing a balance between them.

mAP: Represents the average precision scores' mean across all classes or categories, a commonly utilized metric in object detection tasks.
where is the number of classes or categories, and is the Average Precision for class . mAP is the mean of the average precision (AP) scores across all classes or categories, commonly used in object detection tasks.
mAP@[IoU]: Denotes the average precision means at varying Intersections over Union (IoU) thresholds, assessing the model's effectiveness across diverse IoU requirements.
where is the Average Precision at the IoU threshold for class . mAP@[IoU] is the mean of the average precision at different Intersections over Union (IoU) thresholds, evaluating the model's performance under different IoU requirements.
The comparative analysis of different methods applied on the KITTI and NEXET datasets, including key performance indicators such as precision, F1 score, [email protected], and frames per second (FPS), is presented in Table 4, providing a comprehensive evaluation of their effectiveness in object detection tasks. In the evaluation on the KITTI dataset, the method proposed in this study performed the best, achieving scores of 76.72% in precision, 74.62% in F1 score, 75.32 in [email protected], and 85 in FPS. These results not only demonstrate its superior accuracy but also its significant advantage in processing speed. For the NEXET dataset, our method also displayed outstanding performance, specifically achieving a precision of 74.52%, an F1 score of 71.82%, a [email protected] of 73.12, and an FPS of 72. These outcomes further confirm the consistency of our method's efficiency and accuracy across different testing scenarios. In summary, by adopting the lightweight network model YOLOv8-Lite, we have not only made breakthroughs in accuracy and speed but also ensured the feasibility of the model in practical applications. Particularly in scenarios like autonomous driving, where fast and accurate object detection is required, a high FPS rate means faster response times, which is crucial for safety.
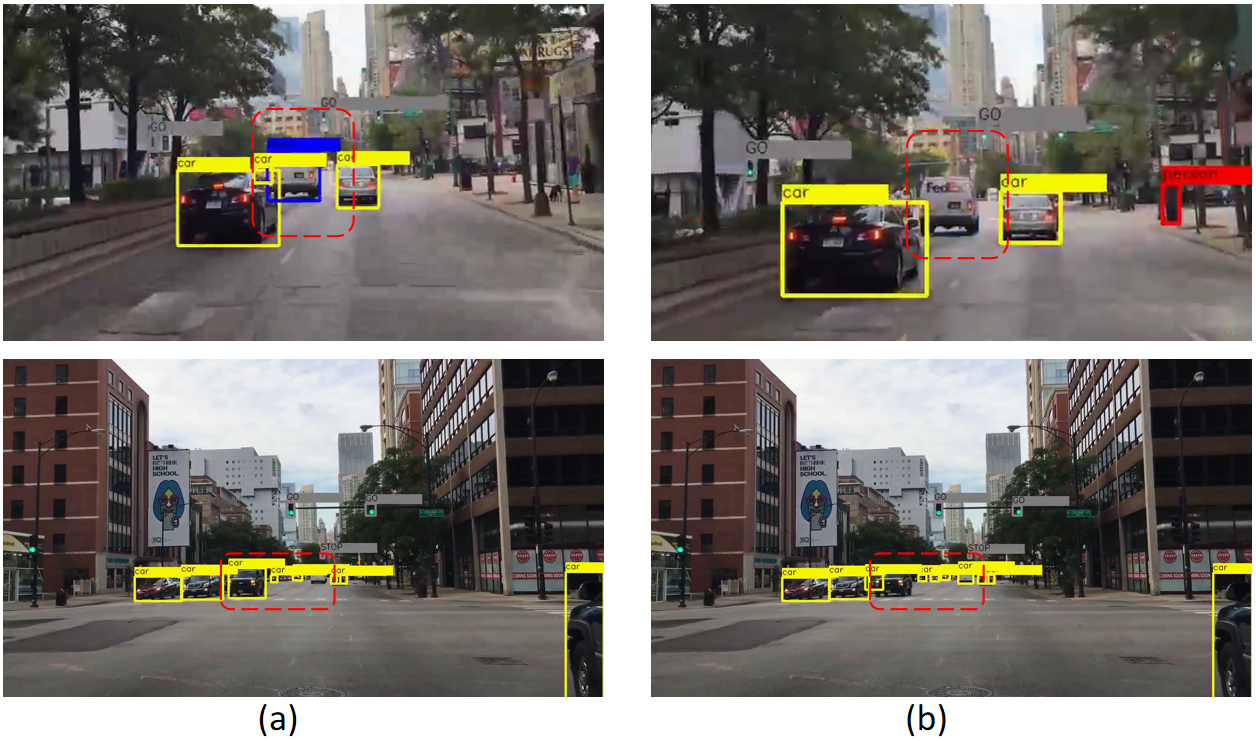
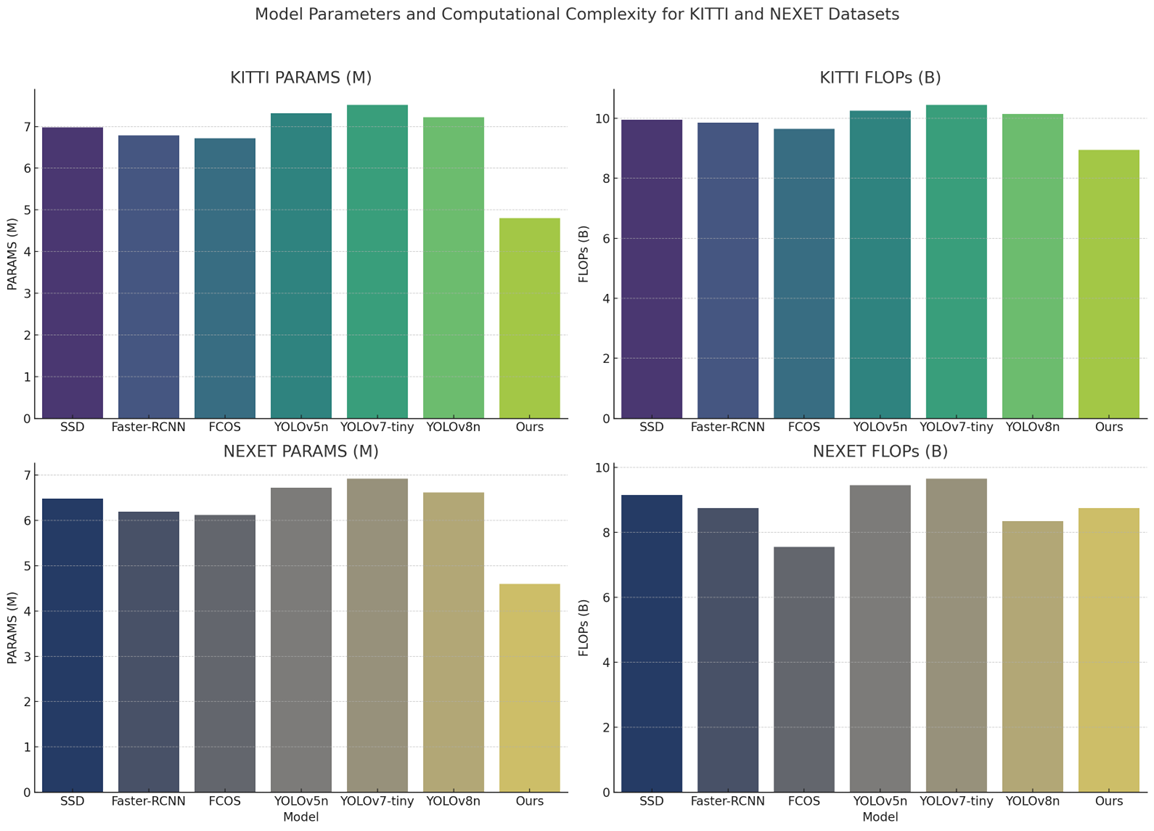
Table 5 presents a comparison of parameter counts and computational complexity for different models on the KITTI and NEXET datasets. It lists each model's number of parameters and floating-point operations (FLOPs), revealing that our proposed model demonstrates lower parameters and FLOPs on both datasets, specifically 4.80M/8.95B (KITTI) and 4.60M/8.75B (NEXET). This indicates that our model maintains high efficiency while reducing computational resource consumption. In contrast, other models like SSD, Faster-RCNN, FCOS, YOLOv5n, YOLOv7-tiny, and YOLOv8n show varying degrees of parameter counts and computational complexity. Figure 7 visualizes these comparisons, further highlighting the results and allowing us to see at a glance that our model has found an ideal balance between high-performance object detection and computational resource efficiency. This not only provides an effective solution for areas such as autonomous driving but also offers valuable insights for future efficient computing in resource-constrained environments.
| Model | KITTI | NEXET | ||
|---|---|---|---|---|
| PARAMS | FLOPs | PARAMS | FLOPs | |
| SSD | 6.98M | 9.95B | 6.48M | 9.15B |
| Faster-RCNN | 6.79M | 9.85B | 6.19M | 8.75B |
| FCOS | 6.72M | 9.65B | 6.12M | 7.55B |
| YOLOv5n | 7.32M | 10.25B | 6.72M | 9.45B |
| YOLOv7-tiny | 7.52M | 10.45B | 6.92M | 9.65B |
| YOLOv8n | 7.22M | 10.15B | 6.62M | 8.35B |
| Ours | 4.80M | 8.95B | 4.60M | 8.75B |
As Table 6 demonstrates, the ablation study results compare the specific impacts of different module combinations on model performance. Through detailed analysis of three core modules—CBAM, TFPN, and FastDet—the experiments reveal their individual and combined effects on precision, F1 score, mean Average Precision ([email protected]), and frames per second (FPS). The baseline experiment (Experiment 1) did not employ any of the new modules, while subsequent experiments progressively introduced CBAM, TFPN, and FastDet to explore the stepwise improvement in model performance. Ultimately, when all modules were integrated in Experiment (5), the model demonstrated optimal performance on both KITTI and NEXET datasets, particularly on the KITTI dataset, where precision, F1 score, [email protected], and FPS were improved to 76.19%, 74.09%, 74.79%, and 85, respectively, with similar significant improvements observed on the NEXET dataset. This series of ablation studies not only verifies the importance of CBAM, TFPN, and FastDet in enhancing model performance but also provides strong evidence for designing efficient object detection models, emphasizing the effectiveness of our model in the field of autonomous driving.

| Modules | KITTI | NEXET | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | CBAM | TFPN | FastDet | Precision | F1 Score | [email protected] | FPS | Precision | F1 Score | [email protected] | FPS |
| (1) | 65.31 | 69.41 | 69.61 | 63 | 70.11 | 67.21 | 68.41 | 51 | |||
| (2) | ✓ | 66.33 | 70.01 | 71.51 | 70 | 73.11 | 67.81 | 70.31 | 62 | ||
| (3) | ✓ | 66.81 | 70.61 | 70.91 | 63 | 64.61 | 69.71 | 69.71 | 51 | ||
| (4) | ✓ | ✓ | 72.01 | 69.71 | 71.71 | 65 | 71.84 | 68.51 | 70.51 | 52 | |
| (5) | ✓ | ✓ | ✓ | 76.19 | 74.09 | 74.79 | 85 | 73.99 | 71.29 | 72.59 | 72 |
Based on the visualization results shown in Figure 8, we can observe that each detection box represents the actual predicted location of objects, with the top of the detection box displaying the predicted category and confidence score. These results demonstrate the outstanding detection performance of the proposed YOLOv8-Lite, especially in terms of recognizing small objects. Compared to the original YOLOv8 model, YOLOv8-Lite significantly improves overall precision while maintaining prediction accuracy. This achievement is primarily attributed to optimizations made in the model architecture, including the introduction of more efficient feature extraction and fusion mechanisms, as well as an optimized network structure designed to reduce computational complexity while enhancing the model's ability to recognize small objects.
Further analysis shows that our network is more comprehensive in object detection. As demonstrated in Figure 9, there are many missed detections by YOLOv8, which we have marked with red boxes. In contrast, our model effectively reduces missed detections, thereby improving the comprehensiveness and accuracy of detection. Additionally, the robustness of our model in handling complex scenes has significantly improved. In environments with dense objects, YOLOv8-Lite not only reduces missed detections but can also more accurately distinguish and locate objects that are close to each other, a task that is challenging for conventional models. This capability of our model is attributed to the in-depth optimization of the feature extraction layers and network structure, enabling the model to more effectively capture subtle feature differences and thus achieve more accurate object detection in complex environments.
However, our network also has some limitations. As shown in Figure 10, it is evident that in conditions of poor lighting or snowy weather, our model cannot comprehensively and accurately detect objects. This phenomenon is mainly due to the significantly reduced visibility of objects in these special environments, making it difficult for the model to capture sufficient feature information, thereby affecting the accuracy and comprehensiveness of detection.
To address this issue, future work needs to consider the introduction of more powerful feature extraction and enhancement techniques, such as using deeper network structures or introducing environment-adaptive algorithms, to improve the model's performance in complex environments. Additionally, leveraging multimodal data (such as radar and infrared images) may also be an effective means to enhance the model's robustness, as these technologies can provide additional environmental information when visual information is insufficient.
In our study, we proposed a lightweight object detection model based on the YOLOv8-Lite framework and validated it on the NEXET and KITTI datasets. Experimental results demonstrate that our model performs well in the task of object detection. This model significantly enhances efficiency and inference speed while reducing the number of parameters. Additionally, through comprehensive evaluation of various metrics, our model exhibits reliability and effectiveness in real-world applications such as autonomous driving. However, our model still has some limitations. Firstly, due to constraints in model parameters and network structure, our model may perform poorly in handling complex scenes and occlusion situations. Secondly, owing to dataset limitations and training strategy choices, the model may encounter overfitting or underfitting issues in specific scenarios, affecting its generalization ability and stability.
Looking ahead, we will continue to improve the model's design and training strategies to enhance its adaptability and robustness in complex scenes. Furthermore, we plan to expand the scale and diversity of the dataset to comprehensively evaluate the model's performance and generalization ability. Additionally, we aim to explore more advanced object detection technologies and algorithms to address the challenges in fields like autonomous driving, contributing to the development of intelligent transportation systems.
 Copyright © 2024 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2024 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. IECE Transactions on Emerging Topics in Artificial Intelligence
ISSN: 3066-1676 (Online) | ISSN: 3066-1668 (Print)
Email: [email protected]

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/iece/