



IECE Transactions on Emerging Topics in Artificial Intelligence
ISSN: 3066-1676 (Online) | ISSN: 3066-1668 (Print)
Email: [email protected]

With the advent of Internet technology and the rapid proliferation of intelligent devices, people's methods of acquiring information have gradually shifted from text to images and videos. Every moment, a vast array of visual content is either actively or passively received by individuals. Among these forms of media, video occupies the largest proportion.
However, due to the immense volume of data and the rich content encompassed within video information, manually sifting through and analyzing each piece of data is evidently impractical. The advancements in deep learning and machine learning have introduced novel approaches to implementing algorithms based on massive datasets. Furthermore, the continued evolution of hardware infrastructure has rendered previously unfeasible algorithms achievable through enhanced computational capabilities. Driven by the synergistic progress of computer hardware and deep learning frameworks, the field of computer vision has experienced remarkable growth in recent years. Its applications have extended across diverse sectors, including transportation, entertainment, medicine, industry, and education.
Currently, major video platforms such as YouTube, iQiyi, Tencent Video, and Youku possess an extensive repository of video content. With the burgeoning number of online video users, there has been a significant upsurge in user-generated content being uploaded to these portals. Consequently, the pressing need to match, filter, and eliminate duplicate videos has emerged as a critical requirement, thus giving rise to the field of video retrieval applications. Evidently, given the sheer volume of online videos, it is impractical to employ manual methods for comparative analysis and filtration. As a result, researchers have turned to machine learning techniques to enhance both the speed and accuracy of video retrieval processes.
As we have known, traditional machine learning feature extraction methods are encumbered by several limitations. Firstly, features such as SIFT keypoints exhibit variable dimensionality, resulting in vastly disparate feature dimensions across different videos, thereby precluding direct utilization of SIFT features for video retrieval [1]. Secondly, the immense volume of video resources inevitably leads to the extraction of a plethora of SIFT features, the storage of which consumes substantial computational resources. These challenges pose significant obstacles in industrial applications. In contrast, deep learning methodologies offer the capability to represent video features in uniform dimensions, yielding global feature representations. When coupled with GPU hardware resources, this approach facilitates efficient video feature extraction and retrieval, dramatically improving both the speed and precision of video retrieval processes.
The advent of deep learning has provided novel approaches to address these challenges. By representing video features in a unified dimension, deep learning methods can extract global features, significantly enhancing retrieval efficiency and accuracy. Nevertheless, the design of a deep learning model capable of adequately capturing the spatiotemporal information in videos remains an urgent technological challenge.
This research aims to resolve key challenges in video retrieval through innovative deep learning architectures. Specifically, our study will focus on addressing the following three issues:
Video Information Optimization: How can we effectively preprocess video data in both temporal and spatial dimensions to maximize the retention of crucial information while minimizing redundancy, thereby providing optimal input for subsequent feature extraction processes?
Dynamic Feature Capture: How can we design and improve 3D convolutional networks (LI3D) to more effectively capture spatiotemporal features in videos, particularly enhancing the model's sensitivity and comprehension of dynamic information when processing complex, dynamic scenes?
Local Feature Integration: How can we develop an innovative feature aggregation mechanism capable of intelligently identifying and integrating key local features in videos, thereby enhancing the model's understanding and recognition of core video content while avoiding excessive information loss or redundancy?
The resolution of these issues will directly impact the performance and efficiency of video retrieval systems, holding significant implications for improving the management and retrieval capabilities of large-scale video data.
This paper is structured as follows: Section 2 provides an overview of related works in the field. Section 3 details the methodology, covering data augmentation preprocessing, extraction of spatiotemporal features in video based on the LI3D network, and spatiotemporal feature extraction utilizing the LI3D-BiLSTM architecture. The experimental setup is described in Section 4, introducing the dataset used and presenting the results and analysis. Finally, Section 5 concludes the paper, summarizing the key findings and implications of the research.
Pattern recognition based on video data has made significant progress, with video databases now featuring more diverse actions and larger data volumes. Video scenarios have evolved from single, simple settings to more complex environments, making video data increasingly representative of real-life situations.
The primary focus of motion pattern recognition algorithms based on video data is how to extract and identify human action features in noisy real-world environments. Andrade-Ambriz et al. [2] achieved human motion state classification by combining Convolutional Neural Networks (CNN) with Support Vector Machines (SVM). Karpathy et al. [3] extended CNN-based human action recognition methods by processing stacked image features with fixed windows. Subsequently, Tran et al. [4] applied 3D CNNs to the Sports-1M dataset, enabling the network to effectively capture and recognize temporal features in videos, thus improving human action recognition accuracy. Zha et al. [5] conducted an in-depth comparative study on different strategies using CNNs in video event detection, significantly enhancing both temporal and spatial feature extraction capabilities of CNNs.
The combination of Convolutional Neural Networks (CNN) and Long Short-Term Memory networks (LSTM) has been increasingly successful in recognizing actions in images. This approach uses CNNs to extract feature information from images and LSTMs to process the temporal relationships between consecutive frames, effectively improving action classification results [6]. Donahue et al. [7] further proposed an LSTM-based autoencoder model that maps input temporal image features to fixed-length representations using an encoding LSTM, then uses one or more decoding LSTMs to classify different actions. This model, applied to human action recognition databases UCF-101 and HMDB-51, demonstrated significant improvements in classification accuracy, especially when sample sizes were limited. Khan et al. [8] introduced regularization to neural networks, normalizing network parameters to ensure different features can share relevant dimensions while maintaining their unique characteristics. Pan et al. [9] used 3D CNNs to extract spatiotemporal features from video frames, then employed LSTMs to capture temporal cues, proposing a model that can adjust weights using a fusion approach.
Many recent motion pattern recognition studies are based on CNNs, LSTMs, and their variants. Yu-Wei Chao et al. [10] used LSTMs to predict dynamic human behaviors from static images, inputting a static RGB image and outputting a series of predictions for future actions. Deo et al. [11] developed an intelligent vehicle gesture recognition system, first using CNNs to extract features from gesture video sequence data, then using long-term recurrent convolution networks to classify the gesture video sequences. Sahoo et al. [12] proposed an online deep learning method for feature extraction from video temporal data to classify human motion patterns, significantly improving learning efficiency compared to traditional batch data processing methods.


In recent years, video-based motion pattern classification has garnered widespread attention in computer vision. With the advancement of deep learning technologies, researchers have proposed various innovative methods to enhance the accuracy and efficiency of video understanding. The extraction and fusion of spatiotemporal features have become key research directions. Bertasius et al. [13] introduced the TimeSformer model, which pioneered the application of pure Transformer architecture to video understanding tasks, demonstrating the advantages of self-attention mechanisms in capturing long-range spatiotemporal dependencies. However, the high computational complexity of this approach limited its application in resource-constrained environments. To address this issue, Fan et al. [14] proposed the Multiscale Vision Transformer (MViT), which achieves multiscale modeling through hierarchical pooling, maintaining high performance while improving computational efficiency.
In self-supervised learning, Tong et al. [15] extended the concept of masked autoencoders to the video domain, proposing the VideoMAE method, which significantly improved the data efficiency of models and opened new avenues for utilizing large-scale unlabeled video data. Lin et al. [16] focused on improving the efficiency of video understanding, proposing a temporal shift attention mechanism that cleverly combines the advantages of the Temporal Shift Module (TSM) and self-attention, effectively capturing long-term spatiotemporal dependencies while maintaining low computational complexity. Ryoo et al. [17] introduced the concept of adaptive spatiotemporal tokenization with their TokenLearner, which can dynamically select important regions based on video content, providing greater flexibility in processing different types of videos. Yang et al. [18] focused on self-supervised learning of motion features with their MotionFormer, emphasizing the crucial role of dynamic information in video understanding. Wei et al. [19] proposed a masked feature prediction method, providing a new paradigm for visual pre-training that can learn richer visual representations applicable to various downstream tasks.
These latest studies not only confirm the core status of spatiotemporal feature extraction and fusion in video motion pattern classification but also propose numerous innovative methods to achieve this goal more effectively. They collectively point to several important trends: the widespread application of Transformer architectures in video understanding, the importance of multiscale spatiotemporal modeling, the potential of self-supervised learning in leveraging large-scale unlabeled data, and ongoing efforts to improve computational efficiency while maintaining high performance.
The main contributions of this paper are as follows:
To enhance the robustness and generalization ability of the network, we researched data augmentation and applied this technique in the data preprocessing stage, achieving spatial and temporal augmentation of video data. Augmentation operations can effectively extract key frames from videos and capture and represent actions in key areas of the video, greatly enhancing the representational capacity of the data.
We studied methods for extracting spatiotemporal features from video data. Video features differ from image features in that they must consider both spatial and temporal dimensions simultaneously. Extracting and modeling only frame-level features would lose the natural connections between consecutive frames in a video. Such isolated features cannot fully represent the content of a video segment. This paper proposes a Lightweight Inception-3D Networks (LI3D) and adopts a transfer learning approach to extract video features. This model can effectively extract both spatial and temporal information from videos.
Dynamic video features differ from static image data. When re-encoding video data, it is crucial to consider the temporal relationships of features. To further enhance the network's ability to recognize temporal features in video data, this paper builds upon the research of Bidirectional Long Short-Term Memory networks (Bi-LSTM). The video feature sequences extracted by the LI3D network are processed through Bi-LSTM for contextual association, enhancing the network's ability to represent temporal data features.
In the process of preprocessing video data, diverse data augmentation strategies were implemented, taking into account the spatiotemporal characteristics of the footage. Temporally, multi-scale frame extraction was employed, enabling effective key frame selection for videos with varying motion dynamics. This approach ensures that the information fed into the network more accurately represents the video content. Spatially, multi-scale video cropping techniques were applied, utilizing three distinct cropping methods to extract specific content from key frames. This methodology not only enhances the feature diversity of the dataset but also facilitates the acquisition of more comprehensive feature information.
Given the intricate temporal relationships inherent in video content, utilizing individual frames extracted from a video fails to adequately represent the comprehensive narrative of the entire sequence. To address this limitation, this paper employs a three-dimensional convolutional neural network as the model for extracting deep features from video data, effectively capturing the temporal information within the footage. This section primarily investigates the temporal data preprocessing procedure prior to network input.
To ensure that the algorithm-extracted features sufficiently express the temporal action information within the video, the most crucial element is providing an abundance of temporally correlated consecutive video frames. This information serves as the model's input, facilitating the extraction of features that encapsulate the entire video's content. However, due to the diversity of action categories in videos, some action information is relatively slow and periodic, such as walking or running, which often spans longer image sequences, as illustrated in Figure 1(a). Conversely, other action information is instantaneous and fleeting, such as archery or basketball shooting, covering relatively shorter sequence lengths, as depicted in Figure 1(b). Consequently, during the video data preprocessing phase, this paper proposes an adaptive multi-temporal scale video frame extraction strategy. This approach is capable of extracting key frames that adequately express video content for videos of varying durations and action characteristics.
This sophisticated frame extraction technique enables the original data input into the network to encapsulate a more comprehensive temporal narrative from the video, thereby achieving the objective of enhancing the diversity of training data. It allows for the acquisition of more nuanced temporal features while maintaining the dimensional integrity of the input data. For each video within the dataset, FFmpeg is employed to transmute the footage into a sequence of individual frames, thus ascertaining the total frame count corresponding to each video Total_frames, the requisite number of frames for model input is denoted as Need_frames. For specific videos, diverse frame extraction strategies are employed.
1) When the total frame count Total_frames does not exceed Need_frames, as illustrated in Figure 1(a), the requisite number Times of traversals Total_frames (denoted by green arrows) and supplementary frames Left_frames (indicated by blue arrows) are calculated. Subsequently, the key frames keyframes destined for model input are derived from Total_frames;
2) When the total number of frames Total_frames in a video exceeds a certain threshold Need_frames, as illustrated in Figure 1(b), we subtract the required number of key frames Need_frames from the total frame Total_frames count to determine the starting point for random frame extraction begin_index (denoted by red point 1). Subsequently, we establish the endpoint end_index (marked as red point 2) by adding the desired total frame count to the initial frame position. Within this feasible range, we proceed to extract the key frames keyframes. The primary algorithmic process is delineated in Algorithm 1.
Data: Total_frames, Need_frames
Result: keyframes
Supplementary frames required: ;
Iteration count for Total_frames: ;
Indicator for frame extraction strategy type: ;
keyframes ;
if then
for in range() do
keyframes.append();
keyframes.append();
end for
else if then
Establish range for frame extraction commencement: ;
Delineate range for frame extraction conclusion: ;
keyframes =
end if
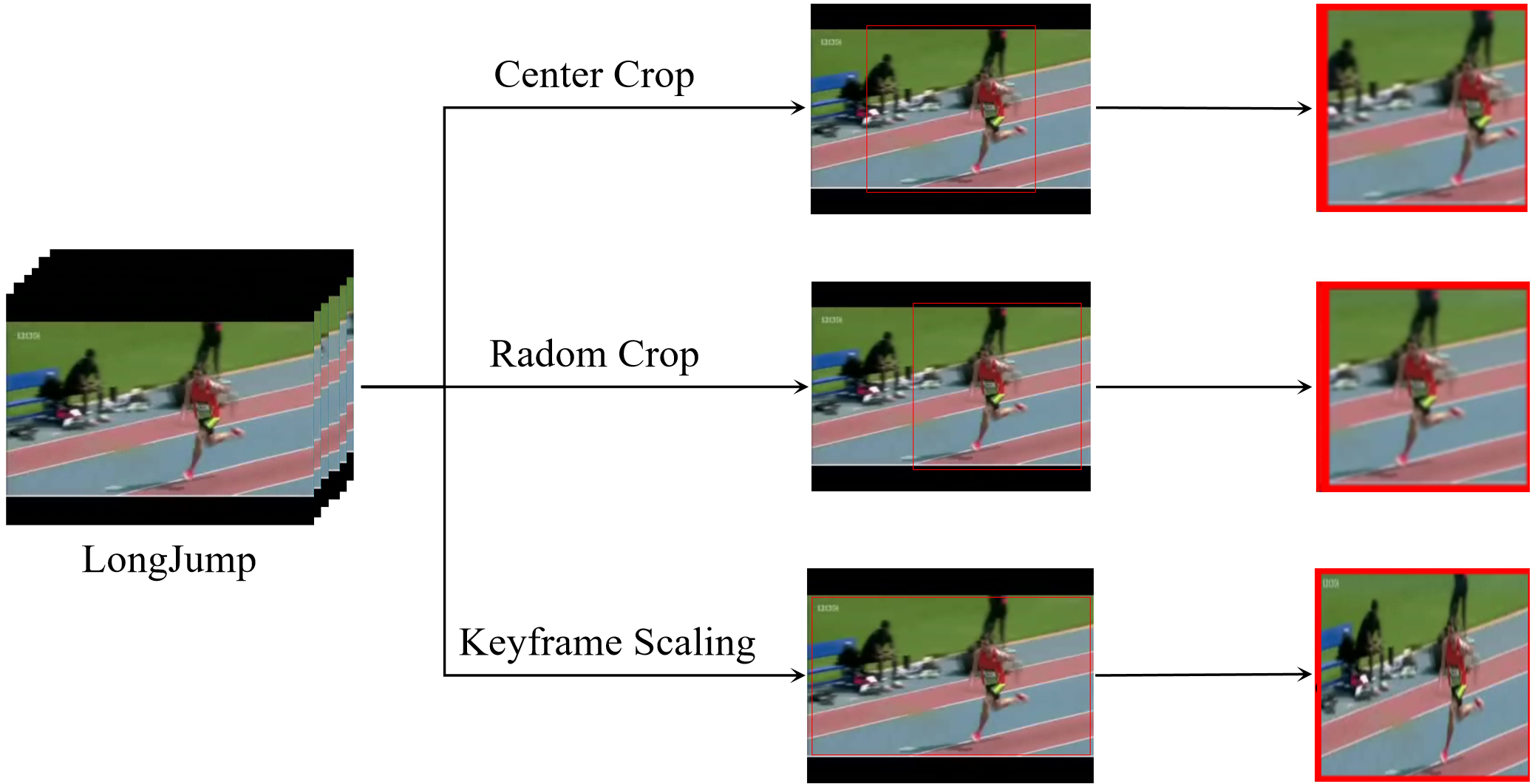
Temporal data augmentation techniques engender a diverse chronological representation within the training dataset, enabling neural networks to extract more comprehensive temporal features. Similarly, in the spatial domain, employing multi-scale cropping procedures enriches each input frame with a plethora of spatial information, facilitating the extraction of more abundant spatial data and thus achieving spatial data augmentation. The multi-scale video cropping strategies utilized in this study, as illustrated in Figure 2, predominantly incorporate three methodologies: central cropping, random cropping, and key frame scaling.
The specific methodologies are as follows:
(1) Key Frame Scaling: This technique involves directly resizing the original image to the dimensions required by the network. This process enhances the image's smoothness and clarity.
(2) Center Cropping: This method extracts the network-required image size from the central region of each key frame. These key frames can thus acquire more crucial information about the image's central area.
(3) Random Cropping: This approach involves randomly cropping the key frame image to obtain an image that conforms to the network's input dimensions. The specific operational process is as follows:
Assuming the required image width is , and the original key frame width is , we can derive a boundary information . Utilizing this boundary information, we can determine the starting position for random cropping, with an interval of . Here, , , and the cropped image width range is .
Through these three spatial data augmentation techniques, we can effectively enhance the network's convergence speed and improve its generalization capabilities.
In the process of image content recognition and classification, feature extraction is pivotal in determining the quality of algorithmic identification. This critical issue has given rise to numerous traditional feature description methods, such as SIFT and HOG. In recent years, with the continuous advancement of deep learning, feature descriptors based on Convolutional Neural Networks (CNNs) have been increasingly employed in image content recognition and classification domains. In contrast to conventional feature descriptors, the process of extracting feature descriptors using CNNs is tantamount to training a series of filters (convolutional kernels). These filters are analogous to detection operators in traditional feature extraction methods. The distinguishing factor lies in the fact that detection operators in traditional methods like SIFT and HOG are typically designed by humans, derived from extensive prior knowledge, whereas these filters are autonomously learned through data-driven processes during neural network training.
In the realm of video feature extraction, 3D convolutional networks are utilized to simultaneously learn temporal and spatial information, yielding descriptors capable of representing both temporal and spatial features concurrently—a feat unattainable through traditional feature extraction methods. However, due to the introduction of convolution operations in the temporal dimension, conventional 3D convolutional neural networks, such as C3D, encounter enormously high computational demands during training. Moreover, the limited availability of video data impedes the provision of superior pre-trained weights. Consequently, C3D's efficiency in extracting video temporal features is suboptimal, and the network's recognition accuracy falls short of excellence.
I3D, however, adeptly addresses these two challenges. Firstly, I3D leverages the Inception-v2 network architecture, which, compared to traditional C3D networks, is deeper and yields more enriched features. Furthermore, I3D can utilize Inception-v2's pre-trained weights from the large-scale ImageNet dataset, significantly reducing the computational requirements for model training and enhancing the network's robustness and generalization capabilities.
The network structure of I3D is derived from Inception-v2 by expanding the dimensions of convolutional kernels, as illustrated in Figure 3. The input video file undergoes 3D convolution and pooling operations for preliminary feature extraction. Subsequently, the extracted video features are further refined through consecutive Inception Module blocks, ensuring that the extracted spatiotemporal features more accurately reflect the genuine motion patterns within the video.
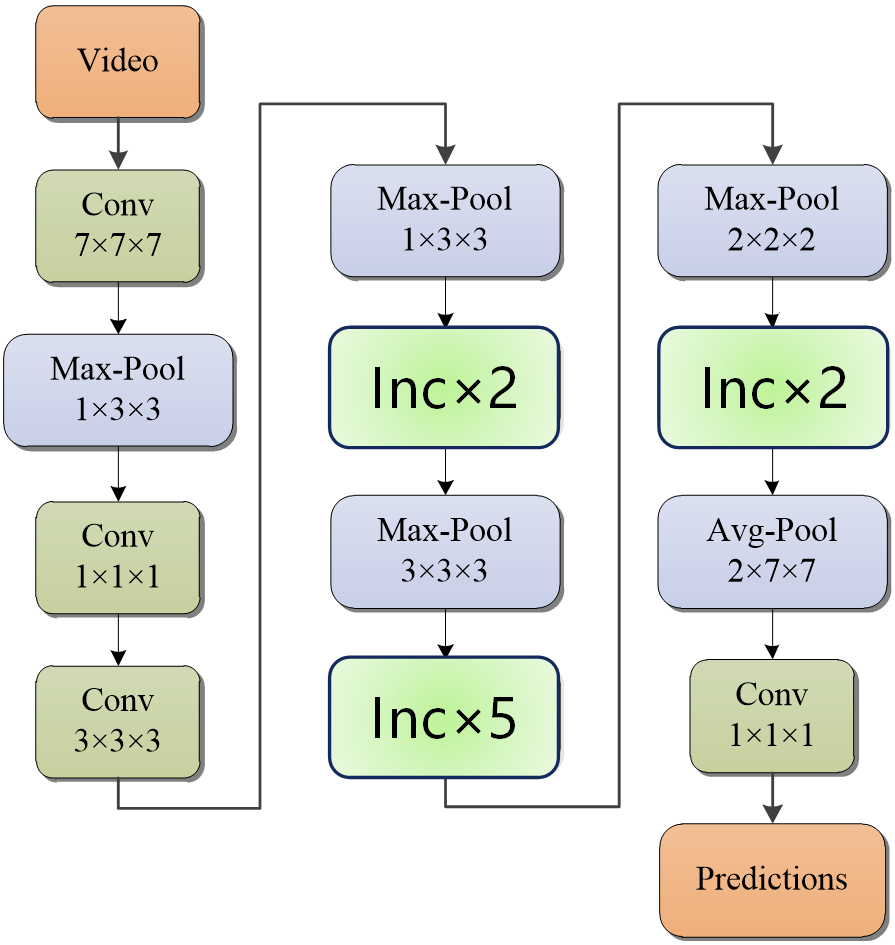
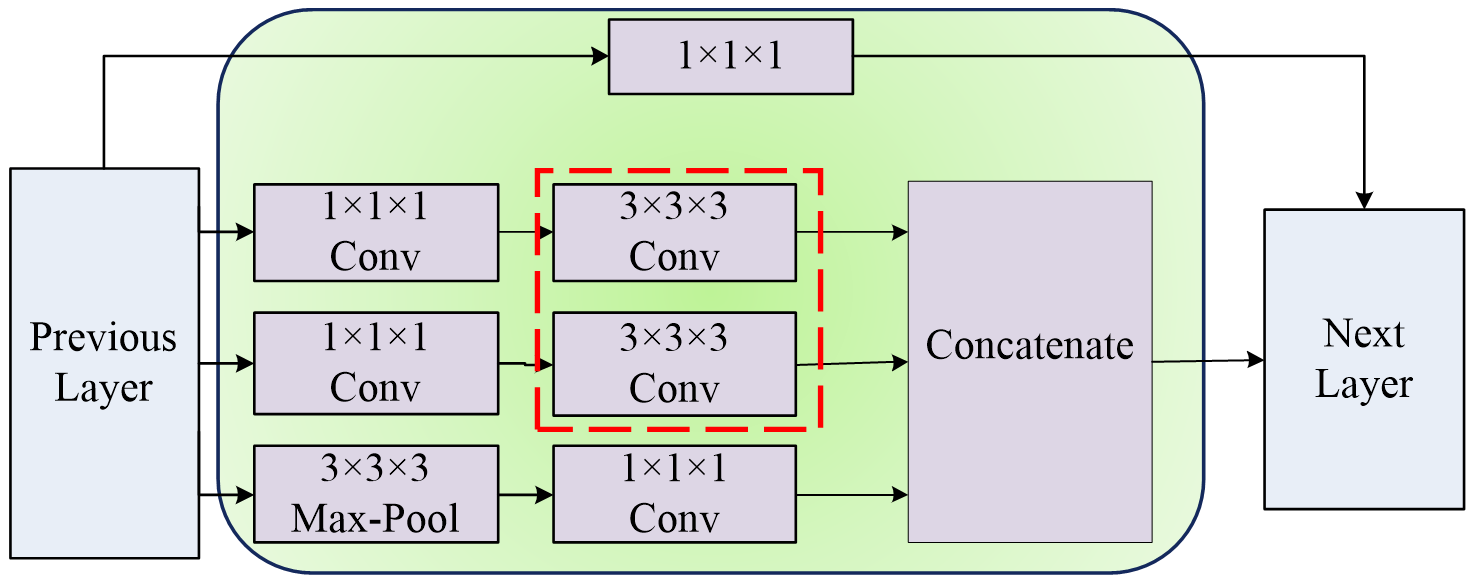
In the realm of deep learning network architectures for extracting spatiotemporal features from videos, I3D boasts two fundamental advantages. Firstly, the I3D model structure incorporates the Inception Module, as illustrated in Figure 4. This module, originally proposed in Inception-v2, enables the network to become both wider and deeper, thus facilitating the acquisition of more diverse spatiotemporal features. Through the Inception Module, the network achieves cross-layer feature fusion, amalgamating these rich feature information streams to enhance the identification of content within images.
Secondly, a notable advantage of the I3D model lies in its utilization of transfer learning principles. By leveraging the ImageNet dataset for pre-training on the Inception Module and subsequently expanding two-dimensional convolution kernels into three dimensions, followed by retraining the network using the Kinetics dataset, this approach not only addresses the limitations of insufficient training data but also rectifies the shortcomings of two-dimensional convolutions in capturing temporal features of video content.
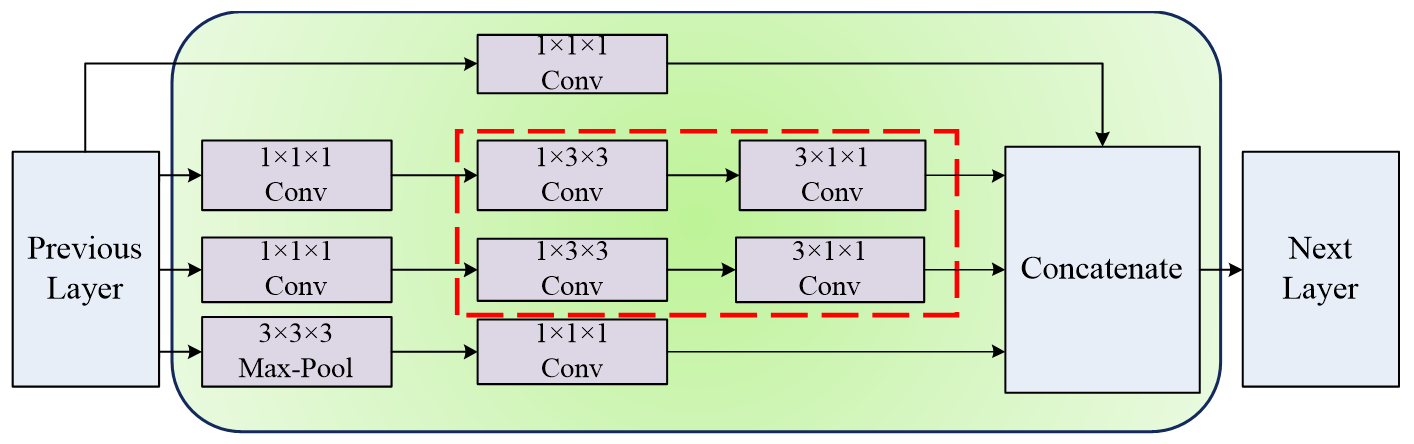
However, the presence of 3x3x3 convolution kernels in the I3D network structure still results in substantial computational complexity, thereby reducing the efficiency of feature extraction. To address this issue, we have modified the Inception module of I3D, as illustrated in Figure 5. Drawing inspiration from the structural pattern of Inception-v3 [20], we have replaced the original 3x3x3 convolutions with a combination of 3x1x1 and 1x3x3 convolution kernels. This modification has reduced our network's parameter count from the initial 12M to 8M, resulting in a more lightweight model. Moreover, the reduction in model parameters enhances the model's generalization capabilities and mitigates the risk of overfitting.
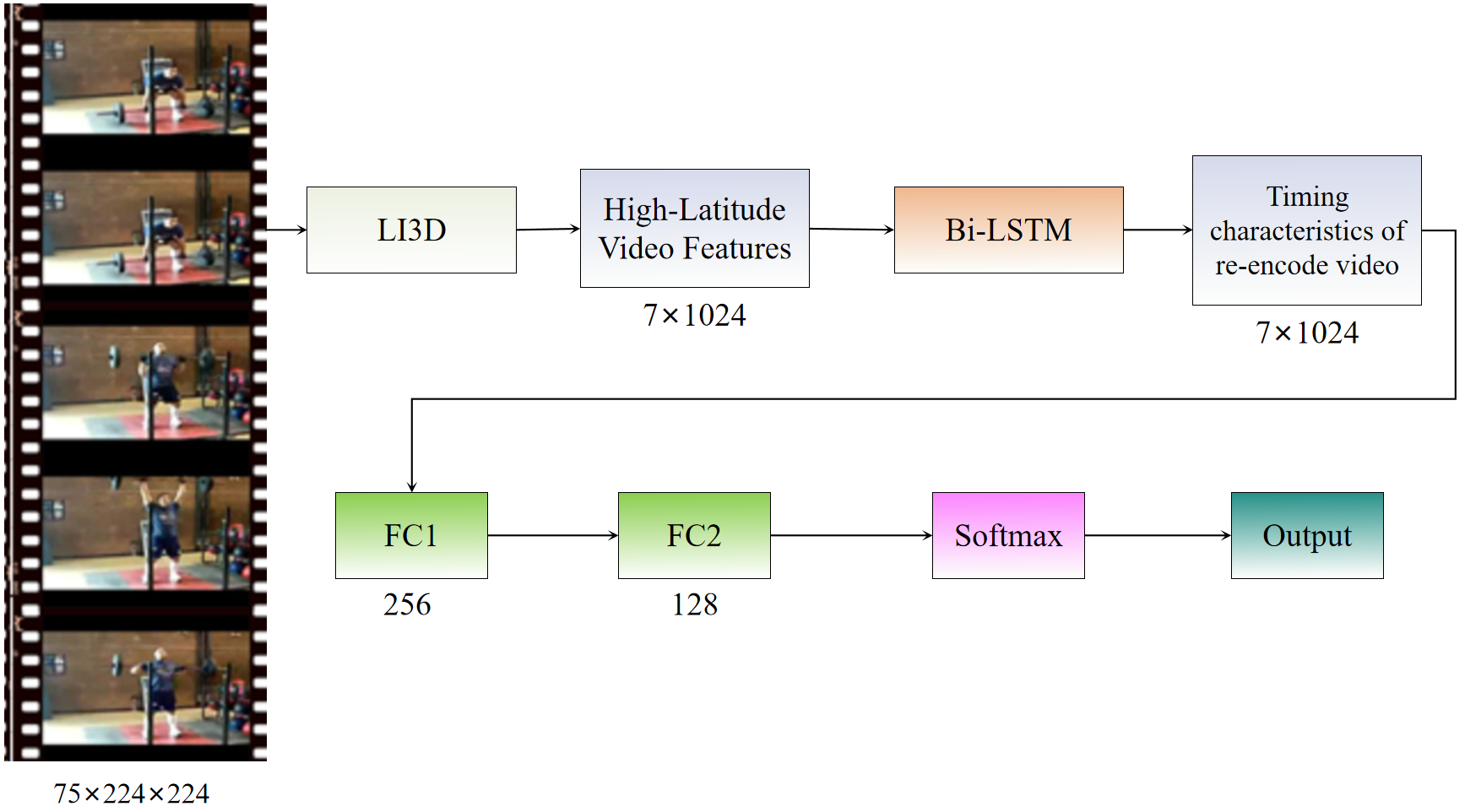
Subsequent experiments utilize the improved network model (LI3D) as the baseline for comparative analysis. We extract 1024-dimensional temporal features from the Average pooling layer of the LI3D model. These features are derived from the input network's temporal video features through convolution and pooling operations. The variable represents the temporal length, with its dimension determined by the length of the input feature clip, while 1024 corresponds to the spatial feature dimension. The LI3D's extraction of video features yields representations encompassing both temporal and spatial dimensions. By subjecting the LI3D-extracted features to Bi-LSTM re-encoding, we fully exploit the contextual relationships within temporal data, further capturing the temporal characteristics of video features and enhancing the representation of video content.
To better utilize the features extracted by LI3D and represent the contextual relationships within video content, this chapter employs a Bidirectional Long Short-Term Memory (Bi-LSTM) module, building upon the foundation of recurrent neural networks (LSTM), to enhance the network's recognition capabilities. The Bi-LSTM structure allows the state at any given moment to be determined by both preceding and subsequent inputs, thus incorporating comprehensive past and future contextual information from every point in the input sequence. This approach more accurately reflects the relationships between frames in video content.
The hidden layer of a Bi-LSTM preserves two values, and , which participate in the network's forward and backward computations, respectively. The final output depends on both and , as illustrated in Figure 6, which demonstrates that during forward computation, the hidden layer's state output at time is related to the previous moment, . Conversely, during backward computation, the hidden layer's state value at time is associated with the subsequent moment's state value, .
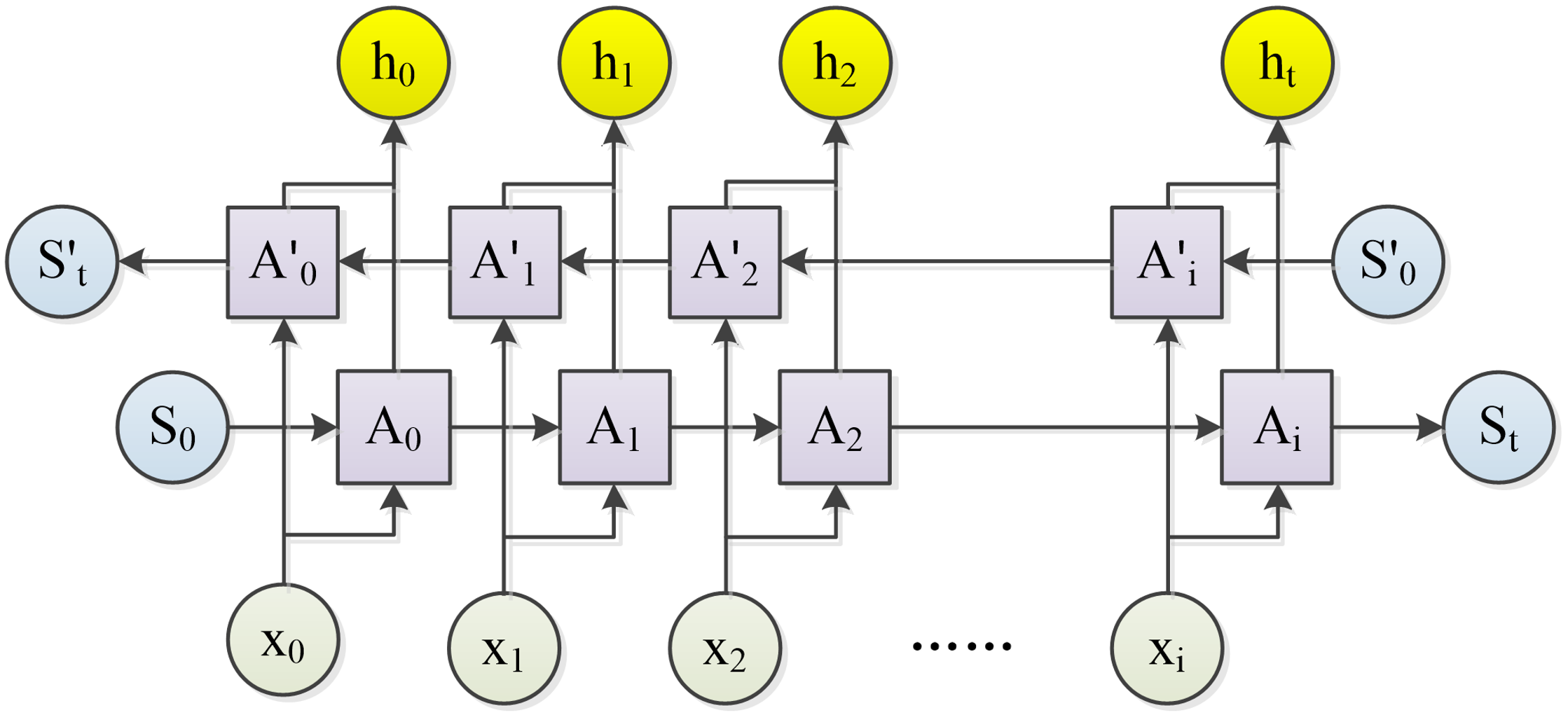
In the feature analysis phase of sequential video data, the utilization of bidirectional recurrent neural networks facilitates a more comprehensive capture of temporal relationships between preceding and subsequent sequences. This approach significantly enhances the representational capabilities of the n-dimensional features obtained during the LI3D feature extraction stage. The specific feature extraction and analysis process is illustrated in Figure 7.
The experimental environment utilized an NVIDIA Tesla P40 GPU server. The study employed the open-source UCF101 dataset, which comprises 13,320 videos primarily extracted from YouTube, with a cumulative duration of 27 hours, encompassing 101 distinct categories. These categories are classified into five broad groups: human-object interaction, bodily movements, human-human interaction, musical instrument performance, and sports activities. Each category contains 25 videos, with each video featuring four to seven action sequences. This research adhered to the third official partitioning method, dividing the dataset into training and testing subsets. The training subset consists of 9,593 videos, encompassing all five aforementioned activity types. An overview of the UCF101 dataset is illustrated in Figure 8.

Case 1: This study compares the performance of the proposed LI3D network structure with the traditional I3D network structure, evaluating them across multiple dimensions such as network parameters, testing time, accuracy, precision, and recall after 50 iterations. The calculations for accuracy, precision, and recall are as follows:
The results of the first experiment, as shown in Table 1, clearly demonstrate that the LI3D network structure effectively reduces the number of network parameters from 12.28M to 8.16M, an overall reduction of 33.6%. This reduction in parameters enhances the network's data fitting capabilities while minimizing the risk of overfitting.
On the UCF101 test set, the accuracy improved from 0.82 to 0.84, precision increased from 0.84 to 0.88, and recall rose from 0.81 to 0.83. Furthermore, the LI3D network's utilization of 3x1x1 and 1x3x3 convolution kernels in place of the I3D network's 3x3x3 kernels significantly reduces computational complexity. This optimization decreases the network's testing time from 2.08s to 1.62s, a reduction of 22.12%, bringing the network's performance closer to real-time efficiency.
| Model |
|
|
Accuracy | Precision | Recall | ||||
|---|---|---|---|---|---|---|---|---|---|
| I3D | 12.28M | 2.80s | 0.82 | 0.84 | 0.81 | ||||
| LI3D | 8.16M | 1.62s | 0.84 | 0.88 | 0.83 |
| Model | Accuracy | Precision | Recall |
|---|---|---|---|
| I3D | 0.85 | 0.88 | 0.84 |
| LI3D | 0.89 | 0.90 | 0.88 |
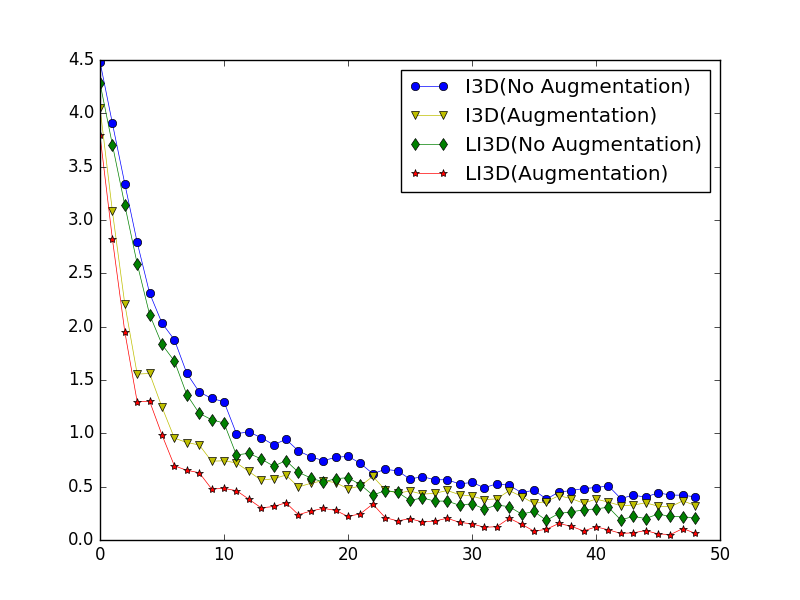
Building upon this foundation, we incorporated data augmentation techniques to compare the changes in accuracy, precision, and recall rates between I3D and LI3D models after 50 iterations. The comparative results are presented in Table 2. It is evident that both I3D and LI3D networks exhibited significant improvements in recognition performance following data augmentation. Moreover, LI3D demonstrated a more pronounced enhancement in accuracy, precision, and recall rates compared to I3D. The three metrics increased from 0.85, 0.88, and 0.84 to 0.89, 0.90, and 0.88, respectively. This indicates that after data augmentation, the LI3D network model was able to maintain a high recall rate while simultaneously achieving a high precision for positive predictions. Figures 9 and 10 illustrate the accuracy and loss function curves during the training phase for I3D and LI3D networks, both before and after data augmentation, under the same 50-iteration conditions.
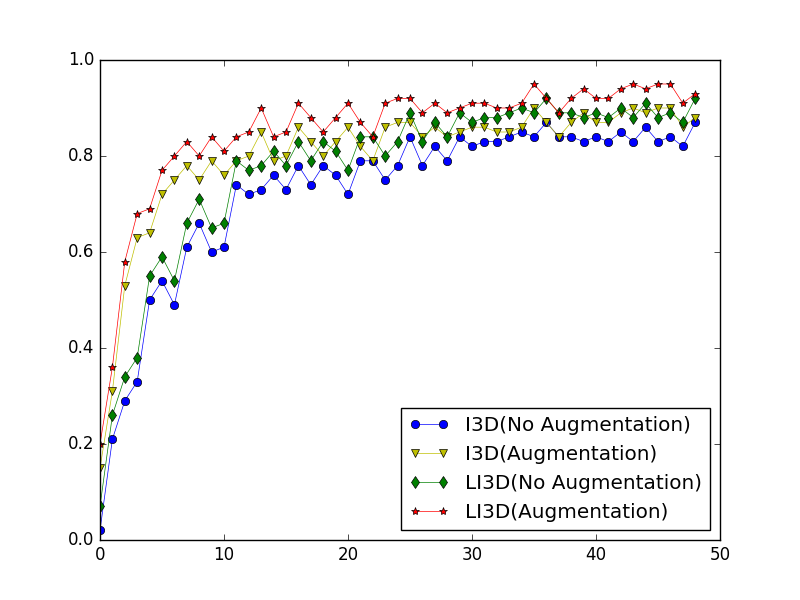
The azure and amber curves in Figure 9 illustrate the accuracy trajectories of the conventional I3D model before and after data augmentation, respectively. It is evident from the graph that post-augmentation, the network's accuracy has experienced a substantial enhancement compared to its prior state. However, it is noteworthy that the post-augmentation accuracy of the I3D model merely attains the pre-augmentation level of the LI3D model. In contrast, the LI3D model, under identical conditions of 50 iterations, achieves a remarkably satisfactory accuracy following data augmentation. This observation underscores the efficacy of data augmentation in elevating network recognition performance. Moreover, when coupled with the fine-tuned LI3D model, the improvement in accuracy is particularly pronounced in comparison to the traditional I3D network.
Figure 10 presents a comparative analysis of the loss function curves for I3D and LI3D models over 50 iterations, both with and without data augmentation. The graph elucidates that post-augmentation, the networks exhibit accelerated convergence, enhanced stability, and improved robustness. Notably, the synergy between the LI3D model and data augmentation strategies yields the most rapid convergence among all configurations examined.
Case 2: Building upon the findings from Experiment I, which revealed that the optimal performance configuration consists of data augmentation strategies coupled with the LI3D model, this subsequent investigation aims to juxtapose the efficacy of LI3D, LI3D-LSTM, and LI3D-BiLSTM models under identical conditions of data augmentation and 50 iterations. The primary objective is to elucidate the enhancement effects of temporal feature analysis on the LI3D model. Table 3 presents a comprehensive comparison of accuracy, precision, and recall metrics for LI3D, LI3D-LSTM, and LI3D-BiLSTM models, all subjected to 50 iterations.
| Model | Accuracy | Precision | Recall |
|---|---|---|---|
| LI3D | 0.85 | 0.86 | 0.84 |
| LI3D-LSTM | 0.86 | 0.89 | 0.87 |
| LI3D-BiLSTM | 0.90 | 0.91 | 0.90 |
From the data presented in the Table 3, it is evident that both LSTM and Bi-LSTM, when applied to temporal features extracted by LI3D, significantly enhance the network's accuracy, precision, and recall rates. This observation underscores the efficacy of LSTM and Bi-LSTM in leveraging temporal relationships within the data, thereby augmenting the features' capacity to represent video content. Moreover, Bi-LSTM demonstrates a superior ability to simultaneously utilize both forward and backward temporal relationships in comparison to LSTM's unidirectional parsing approach, resulting in markedly improved performance.
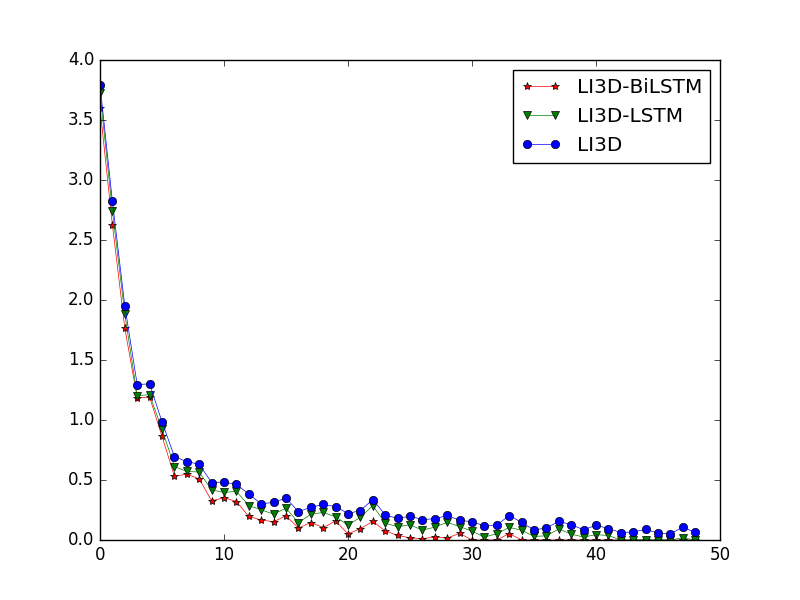
Figures 11 and 12 illustrate the accuracy and loss function curves for LI3D, LI3D-LSTM, and LI3D-BiLSTM under identical conditions of 50 iterations.
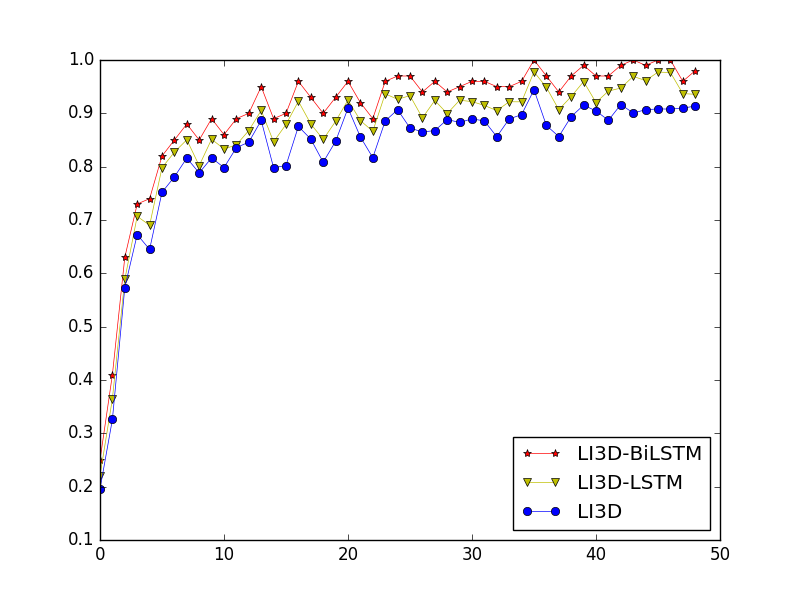
As evident from Figure 11, the LI3D network structure has already achieved a relatively satisfactory level of accuracy. Upon incorporating LSTM for temporal feature re-encoding, the network's accuracy has been further enhanced. Due to Bi-LSTM's ability to utilize features from both time t and t+1 to interpret features at time t, in contrast to LSTM's characteristic of relating features at time t solely to those at time t-1, Bi-LSTM yields feature representations with stronger contextual associations and superior recognition performance. Consequently, LI3D-BiLSTM exhibits higher accuracy compared to LI3D-LSTM.
Figure 12 illustrates that the convergence rate of the LI3D model is considerably slower than that of models incorporating BiLSTM feature interpretation. Networks employing the BiLSTM strategy converge after approximately 30 iterations, indicating that the addition of temporal dimension feature interpretation strategies results in more stable networks with improved robustness.
This research presents an innovative approach to enhance video action recognition, addressing key challenges in the field through a three-pronged strategy. Our method incorporates advanced data preprocessing techniques, a novel lightweight network architecture, and improved temporal feature representation. In the preprocessing stage, we introduced multi-temporal scale video frame extraction and multi-spatial scale video cropping techniques. These methods effectively standardize input formats while preserving crucial content information, significantly improving the model's robustness and generalization capabilities. The implementation of spatial and temporal scale data augmentation further enhanced the extraction of key frames and capture of essential regional actions. Central to our approach is the proposed LI3D architecture, designed for efficient spatio-temporal feature extraction. Coupled with a soft-association feature aggregation module, LI3D demonstrated superior performance in recognizing key actions within videos. The integration of a bidirectional LSTM network further refined the contextual understanding of feature sequences, markedly improving temporal data representation. Experimental results validated the efficacy of our methodology. Comparative analyses of accuracy curves and loss functions revealed that the LI3D model exhibits enhanced stability and faster convergence compared to traditional I3D models. The addition of the BiLSTM module to the LI3D framework yielded substantial improvements in recognition metrics, underlining the effectiveness of our contextual feature association strategy for temporal data representation.
Future research directions include exploring more sophisticated feature aggregation techniques, investigating additional video data augmentation strategies, and extending the application of these methodologies to broader areas within computer vision and multimedia analysis. By continuing to refine and expand upon these techniques, we anticipate further improvements in the accuracy, efficiency, and versatility of video action recognition systems, paving the way for more advanced and reliable applications in real-world scenarios.
 Copyright © 2024 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made.
Copyright © 2024 by the Author(s). Published by Institute of Emerging and Computer Engineers. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. IECE Transactions on Emerging Topics in Artificial Intelligence
ISSN: 3066-1676 (Online) | ISSN: 3066-1668 (Print)
Email: [email protected]

Portico
All published articles are preserved here permanently:
https://www.portico.org/publishers/iece/